Index
Index 정의
Disk I/O를 최소화시키면서 원하는 데이터를 효율적으로 검색하기 위한 자료구조로 Data file과 분리된 index file 에 보관되며, 데이터 필드에 대한 탐색 키값과 record 물리적 위치를 가르키는 포인터로 구성된다.
- Index의 크기는 data file에 비해 휠씬 작다.
- 하나의 data file에 여러 개의 index가 정의될 수 있다. (하나의 희소인덱스와 여러개의 밀집 인덱스를 가질 수 있다. )
- Index가 정의된 table의 필드를 탐색 키라고 한다.
Index 종류
data file 에 대해 직접적으로 index file 이 있는 경우를 단일 단계 인덱스, Index에 대한 또다른 Index 등 여러개의 index file 이 있는 경우를 다단계 인덱스라고 한다.
- 단일 단계 인덱스
- 다단계 인덱스
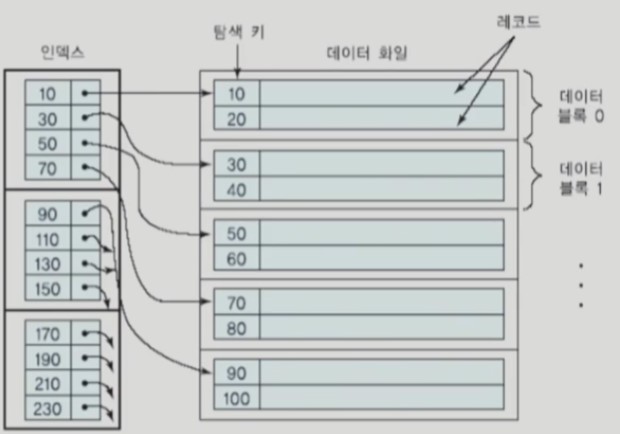
primary index (기본 인덱스)
index key가 data file의 primary key 인 index 로, 희소 인덱스 (sparse index)에 속하는데, 물리적인 주소값에 대한 포인터를 각 Block 당 하나씩 가진다.
primary key에 대해 정렬된 상태로 유지되야 희소 인덱스를 가질 수 있다. (그렇지 않으면 밀집 인덱스를 사용할 수밖에 없음)
clustering index (클러스터링 인덱스)
데이터와 인덱스값이 말그대로 군집화되어, 인덱스가 table의 데이터의 물리적 정렬 순서를 결정한다 . 즉 탐색 키값에 따라 정렬된 table에 대해 정의된다.
데이터 column이 정렬되어 있어야 함으로 table당 하나의 clustering index만 가지고 있다.
clustering index 장점
clustering index는 범위 질의에 유용하다. 범위의 시작 값에 해당하는 index entry를 먼저 찾고, 범위에 속하는 index entry를 따라가면서 record를 검색할떄 디스크에서 읽어오는 block수가 최소화된다.
clustering index 단점
table 에 data가 INSERT된다고하면 해당 table의 지정된 column은 모두 재정렬되야하며 (대참사, 검색에는 성능이 좋지만 입력성능은 최악이다. ) , index 생성시 해당 data file을 다시 정렬한다.
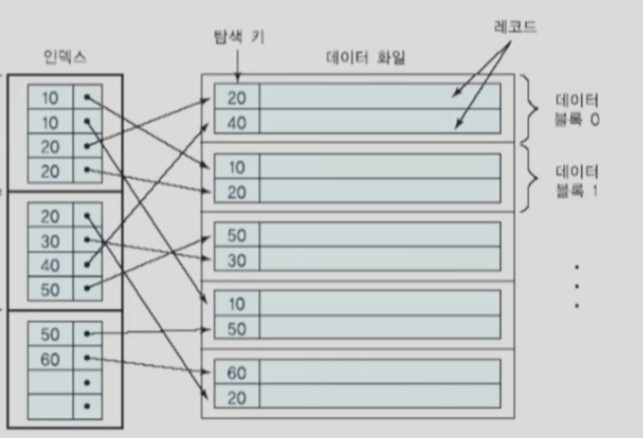
non-clustering index (= secondary index , 보조인덱스)
일반적으로 밀집 인덱스 (dense index)에 속하는데 , index file에서 record 별로 물리적인 주소값에 대한 포인터를 가지고 있다.
non-clustering index 장점
clustering index와 다르게 밀집 인덱스이므로 정렬되지 않은 field도 탐색키로 사용할 수 있다.
non-clustering index 단점
밀집 인덱스이므로, 레코드에 접근할떄 Disk I/O 횟수가 증가한다.
Index 설계 조건
- 갱신이나 삼입이 자주 일어나지 않으며 검색이 빈번한 field에 사용하는게 효과적이다.
- domain cardnality(해당 필드내 상이한 값들의 개수)가 적은 경우에는 index를 사용하지 않는게 효과적이다.
- table의 크기가 작은 경우에는 index를 사용하지 않는게 효과적이다.
B+tree Index
RDB에서 사용되는 Index는 구조에 따라 다음과 같은 3가지로 분류될 수 있다.
- B+tree Index
- Bitmap Index
- Hash Index
이중에서 B+tree가 가장 범용적으로 사용된다. 대표적으로 RDBMS vendor 인 Oracle,PostegrreSql,MySQL 은 이 B+tree를 사용하고 있다.
B+Tree는 B tree에 비해 검색을 효율적으로 만든 자료구조인데,
B+Tree는 다음과 같은 특성을 추가로 갖는다.
- 모든 data가 leef node에 모여있다.
- leef node간에 linked list로 연결되어 있어, leef node간에도 선형검사를 수행할 수 있다.