제한적 직접 실행 (Limited Direct Execution)
제한적 직접 실행 (Limited Direct Execution)
- 제한적 직접 실행과 반대되는 개념인 직접 실행(Direct Execution)은 프로그램을 한번 실행하면 종료될떄까지 cpu상에서 그냥 직접 실행시키는 것을 말합니다.

하지만 직접 실행 방식은 아래와 같은 문제점을 가지고 있습니다.
- 악의적인 process의 경우 os가 제어 불가
- 시분할 기법(time sharing) 구현 불가
+) 참고로 시분할 기법이란 process가 실행될떄 일정한 time quantuam 값내에서만 실행되고, 시간이 초과되면 timer interrupt를 발생시켜 다른 process로 context switching 하는 기법을 말합니다.
- 시스템 자원에 대한 제어 불가
예를 들면 user process가 디스크 입출력 요청이나, cpu , memory와 같은 시스템 자원에 추가할당을 요청할때, user process가 직접 시스템 자원을 꺼내쓴다면 악의적인 process의 경우 시스템 자원을 모두 점유하는 문제점이 있을 것입니다.
kernel mode , user mode
위 시스템 자원에 대한 제어권을 운영체제가 제어하기 위해서 나온 개념이 사용자 모드(user mode) , 커널 모드(kernel mode)입니다.
user process가 실행될떄는 user mode로 전환됩니다. 이 user mode에서는 할 수 있는 일이 제한되는데, 예를 들면 시스템 자원에 대한 요청 (ex)입출력 요청등) 이 제한됩니다.
시스템 자원에 대한 요청은 kernel mode에서 가능합니다. user mode 에서 kernel mode로 전환이 일어나는 메카니즘은 system call입니다.
system call
입출력 요청 , 디스크 읽기와 같은 명령어를 privilliged instruction 이라고 합니다. 이러한 privilliged instruction이 수행되기 위해서는 user process는 system call을 통해 kernel에게 요청해야 합니다.
system call을 실행시키기 위해서는 user process는 trap 특수 명령어를 실행시킴으로서, kernel 안으로 코드가 분기됨과 동시에 user mode 에서 kernel mode로 조정됩니다.
이떄 trap 명령어를 실행한 시점에 각 process의 kernel stack에 해당 user process가 실행중이던 context (register 값, Program counter 값) 를 저장합니다.
user process가 요청한 작업이 끝나면 운영체제는 return-from-trap 특수 명령어를 실행함을 통해서 다시 user mode로 조정하고, 분기되었던 코드로 return 하고, kernel stack의 데이터는 모두 제거됩니다.
trap table
trap 명령어을 통해 kernel mode로 전환하고 운영체제에게 user process가 시스템 자원에 대한 서비스를 요청한다는 게 위 내용들의 정리입니다.
그런데 kernel mode로 전환하고 나서 kernel이 어떤 코드를 실행할지에 대한 정보가 필요합니다. 예를 들면 interrupt 종류가 다양한데, timer interrupt , arithmetic exception … 어떤 interrupt가 발생했을떄,trap 명령어를 통해 어떤 커널의 함수 (handler) 를 실행할지에 대한 정보는 바로 trap table에 있습니다.
모든 system call은 고유의 번호(식별자)를 갖습니다. 따라서 user process가 원하는 system call을 호출하기 위해서는 해당 번호를 통해 trap 명령어를 호출합니다. 이떄 trap table를 보고 trap handler의 주소를 보고 호출합니다.
<1번,segment_fault method address>

전체 제한적 직접 실헁 (limited direct execution ,LDE) 순서를 보면 위 표와 같습니다.
먼저 부팅시에 kernel은 trap table을 초기화하고, cpu는 이 trap table의 위치를 기억해둡니다.
이후에 user process를 실행하기 전에 해당 process에 대한 자료구조(pcb)를 추가하고, 메모리를 할당하는 작업이 일어납니다. user process가 실행중에 system call 요청하면 user process의 실행중인 상태 (context)를 kernel stack에 저장해두고, trap 명령어를 통해서 trap handler를 보고 해당 system call 번호에 맞는 trap handler를 실행합니다. 동시에 kernel mode로 조정됩니다.
system call이 수행되고 나서는 return-from-trap 명령어를 통해 다시 user mode로 돌아가는 데, 이떄 kernel stack에 저장된 user process의 context를 복구하고, user process의 명령어가 실행중이던 위치를 program counter를 보고 다시 찾아가 해당 명령어부터 실행합니다.
time sharing
앞선 방식으로 user process가 직접 시스템 자원을 마음대로 조절할수 없게 권한을 제한하였습니다. 그러면 process간 전환은 어떤 메카니즘으로 해결 가능하냐는 의문이 남아있습니다. 만약 process 간 전환을 제어하지 않는다면 특정 process가 cpu가 독점한다는 문제점이 있습니다.
위처럼 process간 전환을 제어하지 않고, user process가 system call을 호출해 운영체제가 제어권을 가질떄까지 기다리는 협조 방식이 있습니다. 이 방식은 system call이 호출되지 않는 상황이라면 여전히 process간 전환이 정상적으로 일어나지 않는다는 단점이 있습니다.
preemptive scheduling
system call이 없더라도 하드웨어적으로 process로부터 cpu제어권을 뺏는 방법이 있습니다. 바로 일정 time quantuam(대개 10ms) 이후에는 하드웨어 신호를 통해 timer interrupt를 발생시키는 것입니다. interrupt가 발생하게 되면 운영체제는 현재 실행중인 process를 중단시키고, 해당 interrupt에 대한 interrupt handler가 실행됩니다.
process가 중단(blocked)되면 다음에 어떤 process를 실행시켜야 할지 결정해야 합니다. 이부분은 scheduler에 관련된 내용으로 scheduler 종류, 전략도 다양합니다. 어쩄든 scheduler를 통해 실행시킬 process가 결정되고 나면 context swithcing (문맥 교환) 을 통해 이전 process 의 context를 kernel stack에 저장하고, 새로이 실행될 process의 context를 kernel stack으로부터 복구합니다. 이후에는 pc 값을 보고 새로이 실행될 process가 cpu를 할당받아 실행됩니다.
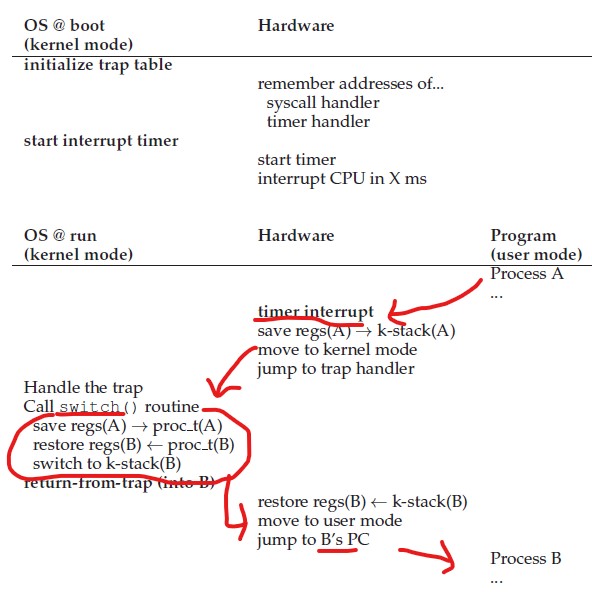
이 과정을 표로 보면 다음과 같습니다.
참고로 context switching 을 하는데도 시간이 소요됩니다. (4~6 마이크로초 단위) 따라서 context switching이 너무 자주 일어나게 되면 오히려 cpu 가 user process의 코드를 실행하는 시간이 줄어들는 오버헤드가 발생합니다.