Apache Kafka Consumer 동작 방식
Consumer
- producer가 전송한 데이터는 kafka broker에 적재되며, consumer가 하는 역할은 broker로부터 data를 가져와 필요한 처리를 수행한다.
1 | public class SimpleConsumer { |
- Consumer Group 을 통해 Consumer의 목적을 구분한다. 동일 기능을 수행하는 app인 경우 하나의 Group으로 묶어서 관리하며, Consumer Group을 기준으로 Consumer Offset을 관리한다. 따라서 subscribe method를 사용해 특정 토픽을 구독하는 경우에 Consumer Group을 선언해야 한다.
- Consumer Group을 선언하지 않으면 어떤 그룹에도 속하지 않는 Consumer로 동작하게 된다.
- Consumer는 poll method를 호출하여 데이터를 가져와 처리한다. 이떄 Duration 타입의 인자값을 받는데, 이 값은 Consumer 버퍼에 데이터를 가져오는 타임아웃 간격을 뜻한다.
파티션 할당 Consumer
- Consumer 운영시 위와 같이 subscribe 형태로 특정 토픽을 구독하는 형태로 사용하는것 외에도 파티션까지 명시적으로 선언할 수 있다. 이때는 Consumer가 특정 Topic의 특정 파티션에 직접적으로 할당됨으로 rebalancing 과정이 안일어나는데 rebalancing에 대한 설명은 아래에 정리하였다.
1
consumer.assign(TOPIC_NAME,PARITITON_NUM);
Consumer 운영 방식
- 1개 이상의 Consumer로 이루어진 Consumer Group을 운영한다. 이떄 Consumer들은 Topic의 1개 이상의 파티션들에 할당되어 데이터를 가져갈 수 있다.
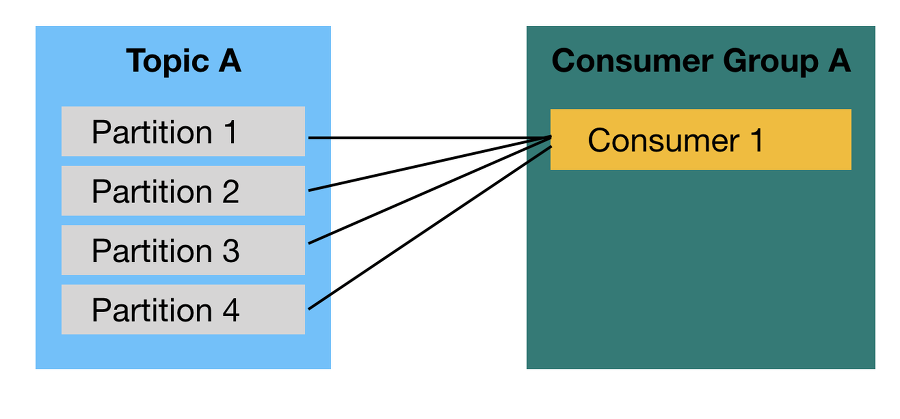
이떄 1개의 파티션은 최대 1개의 Consumer에 할당가능한 반면 1개의 Consumer는 여러 개의 Partition에 할당될 수 있다. 따라서 Consumer Group의 Consumer개수는 가져가고자 하는 Topic의 파티션 개수보다 같거나 작아야 한다.
물론 Consumer개수가 파티션의 개수보다 많게 설정할 수는 있겠지만, 파티션은 1개의 Consumer까지만 가질 수 있기 때문에 놀고 있는 Consumer는 Thread만 차지하고 아무 데이터도 처리하지 않음으로 불필요하다.
Consumer Group은 다른 Consumer Group과 격리되는 특징을 가지고 있다. 따라서 Kafka Producer가 보낸 데이터를 각기 다른 역할을 하는 Consumer Group끼리 영향을 받지 않게 처리할 수 있다는 장점을 가진다.
Rebalancing
Rebalancing : Consumer Group으로 이루어진 Consumer 들 중 일부 Consumer에 장애가 발생하면 , 장애가 발생한 Consumer에 할당된 partition은 장애가 발생하지 않은 Consumer에 소유권이 넘어가는 것
Consumer가 추가되거나 장애발생으로 제외되는 상황에서 발생한다.
Rebalancing 발생 시 Consumer들이 Topic의 데이터를 읽을 수 없기 떄문에 빈번히 Rebalancing이 일어나는 상황은 피해야 한다.
Broker중 한 대가 Group Coordinator(그룹 조정자)로서, Rebalancing을 발동시키는 역할을 한다.
Rebalancing 직전에 데이터를 커밋하지 않아서, consumer가 처리했던 데이터의 오프셋이 기록되지 않고, 또 다시 데이터를 중복처리하는 경우가 생길수도 있다.
org.apache.kafka.clients.consumer.ConsumerRebalanceListener는 rebalancing 직후 , 직전에 호출되는 method를 가지고 있다.
1 | public class RebalanceListener implements ConsumerRebalanceListener { |
Commit
Consumer는 Broker로부터 Data를 어디까지 가져갔는지 Commit을 통해 기록한다.
특정 Topic의 Partition을 어떤 Consumer Group 이 몇 번쨰까지 가져갔는지 Broker 내부에서 사용되는 내부 토픽에 기록된다.
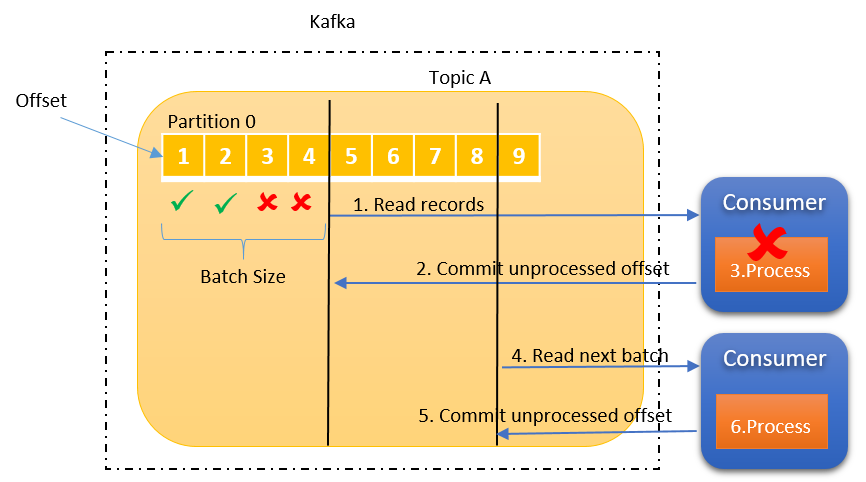
- offset commit은 Consumer Application에서 명시적/비명시적으로 수행가능한데, default는 poll method가 수행될때 일정간격마다 offset을 commit하도록 설정되어 있다. 이를
비명시 오프셋 커밋이라고 부른다.
1 | enable.auto.commit=true |
비명시 오프셋 커밋의 장점은 poll method 실행시 auto.commit.interval.ms 설정값 이후면 오프셋을 자동으로 커밋해주어, 코드상 수정이 필요없지만 반대로 단점은 poll method 실행 이후에 rebalancing이나 consumer 장애발생시에 오프셋이 커밋되지 않아, 데이터 중복이나 유실이 일어날 수 있는 가능성이 있다.
명시적으로 오프셋 커밋을 수행하려면 commitSync method를 통해 poll method를 통해 반환된 record의 가장 마지막 오프셋을 기준으로 커밋을 수행하면 된다. commitSync method는 동기적으로 broker에게 응답을 기다리지만 이를 비동기적으로 수행하고 싶다면 commitAsync method를 실행하면 된다.
동기 오프셋 커밋
1 | configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false); |
- Broker로 Commit을 요청한 이후에 Commit이 완료될떄까지 기다린다. 따라서 비동기 오프셋 커밋보다 데이터 처리량은 떨어진다.
가장 최근에 받아온 레코드의 오프셋을 커밋하는 경우
1 | ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1)); |
개별 레코드 단위로 커밋하는 경우로, topic,partition,offset등의 정보를 담은 map을 파라미터로 넘겨준다. 이때 offset은 넘겨준값부터 레코드를 넘겨주기 떄문에 + 1 한 값을 넣는다.
1 | ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1)); |
비동기 오프셋 커밋
- Broker로 Commit을 요청한 이후에 응답을 기다리지 않고, 데이터를 처리한다.
1 | consumer.commitAsync(); |
- consumer.commitAsync method는 콜백 인터페이스를 제공하며 , 비동기요청이 완료되었을때 수행할 행동을 지정할 수 있다.
1 | consumer.commitAsync(new OffsetCommitCallback() { |
Fetcher instance
1 | consumer.poll(Durtaion.ofSeconds(1)); |
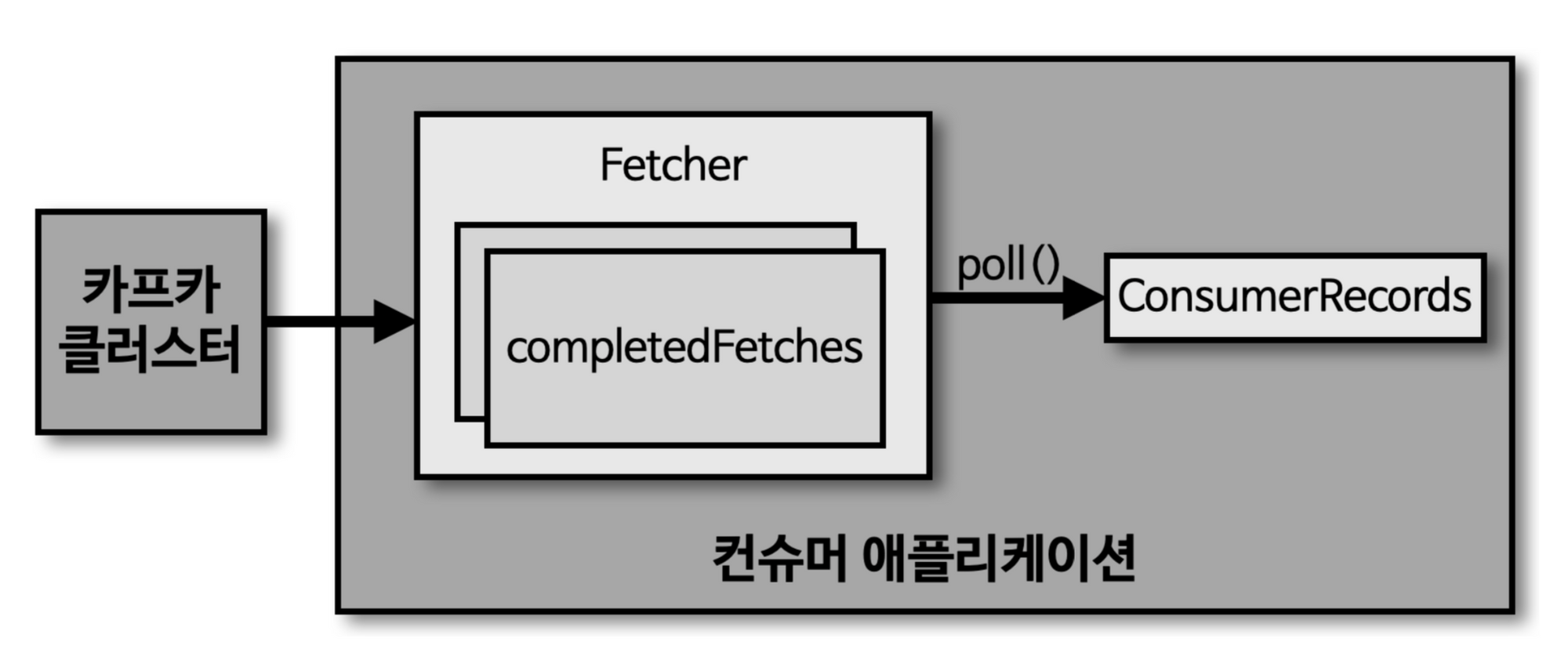
consumer는 poll method를 통해 record를 반환받지만, 실제로 이 method가 실행될떄 Broker cluser로부터 데이터를 가져오는 것이 아니라, Consumer Application 실행시점에 내부에서 미리 Fetcher Instance가 생성되어 poll method 호출전에 record를 미리 내부 Queue로 가져온다.
따라서 poll method는 Fetcher instace의 queue에 있는 record를 반환받는 것이다.
Consumer Option
필수 옵션
- bootstrap.servers (broker 서버주소) , key.deserializer , value.deserializer
선택 옵션
- group.id : consumer group id 지정 , subscribe method로 topic 구독시 필수 옵션임
- auto.offset.reset : consumer group이 특정 파티션을 읽을때, 저장된 consumer offset이 없는 경우 해당 옵션이 사용됨.
- latest : 가장 최근에 넣은 오프셋부터 읽음
- earliest : 가장 오래전에 넣은 오프셋부터 읽음
- none : consumer group의 커밋한 기록이 있으면 기존 커밋기록부터 읽고, 없으면 오류 반환
- enable.auto.commit : 자동커밋,수동커밋여부 선택 (기본값은 자동커밋)
- auto.commit.interval.ms : 자동커밋일 경우 커밋 간격 (기본값은 5초)
- max.poll.records : poll method를 통해 반환되는 레코드 개수 (기본값은 500개)
Consumer 종료 처리
- kafka에서는 Consumer 가 사용하는 리소스를 반환하고 안전하게 정리하기 위해 wakeup method를 제공하는데, wakeup method 이후에 poll method가 호출되면 WakeupException이 터진다.
1 | try{ |