Transaction
Transaction은 작업의 논리적인 단위로서 , 예를 들면 은행에서 출금 후 입금을 한다고 가정하였을떄 실제로 DB query문은 여러 번 나가겠지만 하나의 논리적인 작업 단위로 볼 수 있다.
Transaction이 필요한 이유는 데이터베이스 연산 중간에 일관되지 않은 상태가 존재하기 떄문이다. 2개의 연산중에 하나만 수행되고 하나는 아직 수행되지 않은 상태가 존재할 수도 있다.
따라서 데이터베이스는 작업의 완전성을 보장해주기 위해서 , 일련의 연산들을 사용자 입장에서 마치 단일 연산인것처럼 보이게 해준다.
추가로 transaction은 다음과 같은 특징을 갖는다.
- Transaction은 recovery 단위이다. 실제로 DB에 쓰여지는 과정에서 system failure시 write ahead log (WAL) 라고 하는데 log라는 자료구조에 먼저 transaction을 쓰고나서 commit처리를 해준다. 즉 commit 이후에 system failure시에는 이 log를 보고 복구가 가능하다.
- 아래에 Transaction 특성 중에 Isolation (독립성) 이 있다. 서로 다른 transaction은 독립적으로 수행될 수 있어야 하는데 , 이를 위해서는 concurrency control (동시성 제어) mechanism 이 필요하다.
Transaction의 특성 (ACID)
Transaciton 은 작업의 완전성을 보장하기 위해서 다음과 같은 4개의 특성을 갖는다.
- Atomicity (원자성): 원자성을 가지므로, 전부 실행되거나 (commit) 혹은 전부 실행되지 않는다 (rollback)
- Consistency(일관성) : Transaction은 데이터베이스의 일관성을 유지해야 한다. 즉 일관된 상태에서 일관된 상태로 변환해야 한다.
- Isolation(독립성): Transaction은 서로 독립적으로 수행될 수 있어야 한다.
- Durability(지속성) : Transaction이 commit되면 DB에 영구적으로 저장되야 한다.
Transaction 상태
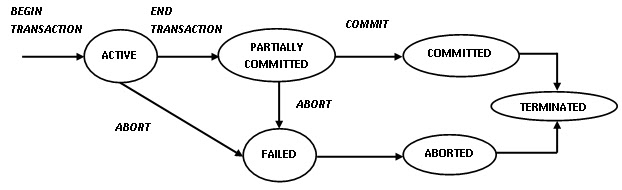
transaction은 다음과 같은 상태를 가진다.
- Active state : transaction이 아직 실행중인 상태
- Partially committed state : transaction의 마지막 연산까지 전부 수행되었지만 commit 하기전의 상태
- Failed : transaction중 오류가 발생해 중단된 상태
- committed : transaction이 성공적으로 종료되어서 DB에 영구적으로 반영된 상태
- aborted : transaction이 비정상적으로 종료되어서 rollback 연산을 통해서 작업을 취소하여 transaction 수행 이전의 일관된 DB 상태로 돌아간 상태
transaction의 병행수행 제어 기법 (concurrency control mechanism )
다른말로 동시성 제어인데, 여러가지 transaction 이 공유자원 (DB 데이터)를 동시에 접근할떄 여러가지 문제가 발생할 수 있다
대표적으로 다음과 같은 문제가 생길 수 있다
- lost update problem(갱신 분실 문제) : transaction A 가 수행한 update가 transaction B가 수행한 update를 덮어씌움.
- uncommitted dependency problem (비완료 의존성 문제) : transaction A 가 완료되지 않은 상태에서 갱신한 데이터를 transaction B 가 갱신했는데, transaction A가 rollback됨.