OSI 7 계층과 TCP/IP
Protocol
- 네트워크에서는 통신할떄의 규약을 protocol이라고 함.
- 최근 이더넷 - TCP/IP 기반 protocol로 획일화되고 있는 추세이다.
- 물리적인 측면 : 데이터 전송 매체 , 신호 규약 , 회선 규격 등 이더넷이 널리 쓰인다.
- 논리적인 측면 : 장치들간에 통신하기 위한 protocol 규격으로 TCP/IP가 널리 쓰인다.
과거에는 네트워크 환경과 컴퓨팅 환경이 열악해 한정된 자원으로 최대한 효율적인 protocol을 정의하고 사용해야 했음. 따라서 대부분의 protocol이 문자 기반이 아닌 2진수 bit 기반으로 만들어졌음. application level의 protocol은 bit 기반이 아닌 문자기반으로 많이 사용되고 있음. ex) HTTP,SMTP
문자기반으로 사용할 경우, 효율성은 bit 기반 protocol보다 많이 떨어지지만 다양한 확장이 가능하다.
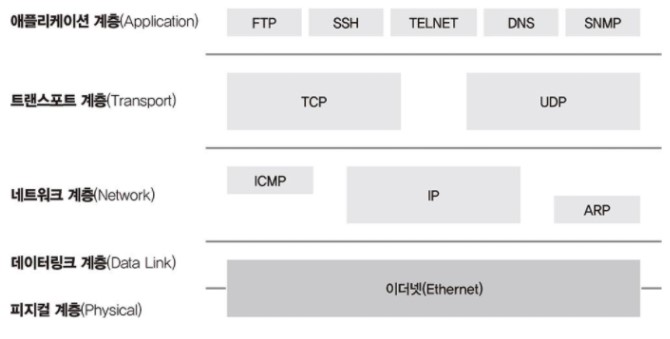
TCP/IP protocol stack
TCP(transport 계층)와 IP(network 계층)는 별도의 계층에서 동작하는 protocol 이지만 함께 사용하고 있는데 , 이런 프로토콜의 묶음을 protocol stack이라고 부름
TCP/IP protocol stack은 총 4개 부분으로 나뉜다.
OSI 7계층과 TCP/IP
- OSI 7계층은 네트워크의 주요 reference model로 활용되고 있지만, 현재는 대부분의 protocol이 TCP/IP protocol stack 기반으로 되어 있다.
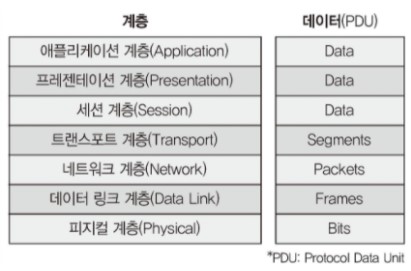
- 계층별로 표준화된 protocol을 개발함으로서 네트워크 구성 요소들을 모듈화 할 수 있다.
- 모듈화함으로서 기존에 다른 계층의 protocol들과 연동해 사용할 수 있다.
OSI 7계층은 다시 2가지 계층으로 나뉜다.
- Data Flow layer (Lower Layer) : 1~4 계층
- Application Layer (Upper Layer) : 5~7 계층
Data flow layer 는 데이터를 상대방에게 잘 전달하는 역할을 가지고 있으며 , application layer는 데이터를 잘 표현하는데 역할을 가지고 있다. 따라서 네트워크 엔지니어는 Data flow layer 을 고려하고, application 개발자는 application layer를 고려한다.

OSI 7계층과 TCP/IP protocol stack의 차이점
- OSI reference model은 7 계층으로 이루어진 반면, TCP/IP 모델은 4계층으로 구분된다.
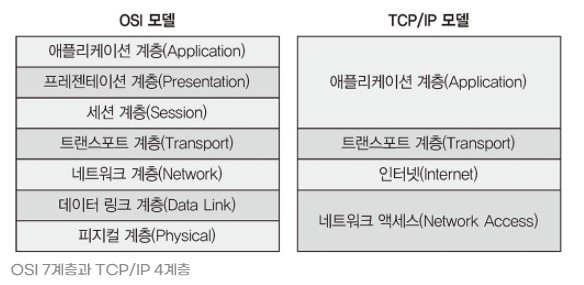
- TCPI/IP 모델은 상위 3개 계층 (application,presentation,session) 은 하나의 application 계층으로 묶고, 하위 2개 계층 (physical , data link) 계층을 하나의 network access 계층으로 분류한다.