Transaction은 ACID 라 하는 원자성 (Atomicity) , 일관성 (Consistency) , 격리성 (Isolation) , 지속성 (Durability) 을 보장해야 한다.
이중에 Transaction 격리 수준에 관련된 ACID 특성인 격리성만 간략하게 정리하면 , 동시에 실행되는 트랜잭션이 서로에게 영향을 미치도록 격리한다는 뜻이다.
왜 격리 수준을 나누어서 관리하는가?
격리성이란 트랜잭션이 서로에게 영향을 미치지 않도록 해야 한다는 성질인데, 이를 완벽하게 100% 보장하려면 동시성과 관련된 성능 저하가 야기된다. 예를 들면 모든 트랜잭션이 순차적으로 실행되고 끝나야만 이를 보장할 수 있다.
ANSI 표준 Transaction 격리 수준
ANSI 표준에서는 트랜잭션 격리 수준을 4단계로 나누어서 정의하고 있다.
READ UNCOMMITED (커밋되지 않은 읽기)
READ COMMITTED (커밋된 읽기)
REPEATABLE READ (반복 가능한 읽기)
SERIALIZABLE (직렬화 가능)
(1->4으로 갈수록 격리 수준이 높아지고, 동시성은 떨어진다. )
READ UNCOMMITED
커밋하지 않은 데이터를 읽을 수 있다.
Transaction A가 Transaction B 가 커밋하기 전에 수정한 데이터를 조회할 수 있다.
만약 Transaction B가 데이터를 수정하고 롤백을 해버렸는데, Transaction A는 이 ROLLBACK한 데이터를 참조하고 있는 경우 데이터 정합성 문제가 발생할 수 있다. (Dirty Read)
READ COMMITED
커밋한 데이터만 읽을 수 있다.
Dirty Read가 발생하지 않는다.
만약 Transaction A 가 데이터를 수정하고 Commit하면 , Transaction B가 Transaction A가 변경하기 전의 데이터를 읽고, Transaction A가 변경하고 나서 커밋한 뒤에 데이터를 다시 읽었을때, 값이 다르다. 즉 Tranascation B가 실행되는 도중에 Transaction A 가 값을 변경하고 커밋해버리면 다시 읽었을떄 값이 달라지는 문제이다. (NON-REPEATABLE READ)
보통 데이터베이스는 READ COMMITED 격리 수준을 기본으로 제공한다.
REPEATABLE READ
동일 Trnasaction 내에서 한번 조회한 데이터를 다시 조회할때도 동일한 값이 조회되는 격리 수준이다. 즉 NON-REPEATABLE READ가 발생하지 않는다.
만약 Transaction B가 특정 결과집합을 조회하고 나서, Transaction A가 데이터를 insert 하고 커밋하면 , Transaction B가 결과집합을 다시 조회하였을때, 데이터 값이 변경되진 않지만 추가된 상태를 읽는다. (PHANTOM READ)
SERIALIZABLE
가장 엄격한 Transaction 격리 수준으로 Dirty Read , NON-REPEATABLE READ , PHANTOM READ 어떠한 문제도 발생하지 않는다.
read - only mode의 경우에는 serializable isolation level과 유사하나 , SYS 유저가 아닌 경우에는 데이터 변경을 허용하지 않는다. 즉 일반 유저는 serializable isolation level 에서 데이터 변경까지 허용이 불가능한 격리 수준이 가장 높은 모드이다.
Record 와 같은 복합형 데이터 타입이며, 동시에 여러 로우에 해당되는 데이터를 가질 수 있다.
객체지향언어의 클래스와 유사하다. 클래스처럼 생성자를 통해 초기화를 할 수 있고 (연관배열은 불가능), built-in 함수와 procedure로 구성된 collection 메소드를 제공한다.
method를 통해서 collection 내 값을 수정,삭제할 수 있다.
Collection의 종류
Oracle에서 제공하는 Collection 타입은 구조에 따라 3가지로 나뉜다.
연관 배열 (Associative Array)
VARRAY (Variable-Size Array)
중첩 테이블
연관 배열 (Associative Array)
키-값 pair로 구성된 Collection. Key를 인덱스라고도 부르기 떄문에 index-by 테이블이라고도 한다.
연관 배열 선언 문법
1
TYPE 연관배열명 IS TABLE OF 값타입 INDEX BY 인덱스(키)타입;
주의할점은 값타입은 어떠한 타입도 올 수 있지만 , 인덱스(키) 타입은 문자형,PLS_INTEGER 타입만 올 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
DECLARE -- 연관 배열 타입 선언 TYPE av_type ISTABLEOF VARCHAR2(40) INDEX BY PLS_INTEGER; -- 연관 배열 변수 선언 vav_test av_type; BEGIN -- 연관 배열에 값 할당 vav_test(10) :='value of key 10'; vav_test(20) :='value of key 20'; -- 연관 배열의 값 조회 DBMS_OUTPUT.PUT_LINE(vav_test(10)); DBMS_OUTPUT.PUT_LINE(vav_test(20)); END;
위 예제에서 보다시피 연관 배열의 요소값은 연관배열변수명(키) 형태로 접근 가능하다.
연관배열에 값을 입력할때 마다 내부적으로는 인덱스 값을 기준으로 정렬된다.
VARRY (Variable Size Array , 가변 길이 배열)
연관 배열과 다르게 크기에 제한이 존재한다.
키 값을 개발자가 명시하는게 아니라 DB AUTO_INCREMENT처럼 자동으로 순번이 증가한다.
VARRY 선언 문법
1
TYPE VARRY 명 IS VARRAY(최대요소개수) OF 값타입; -- ex) VARRY(10) : 최대 요소를 10개 가지는 가변 길이 배열
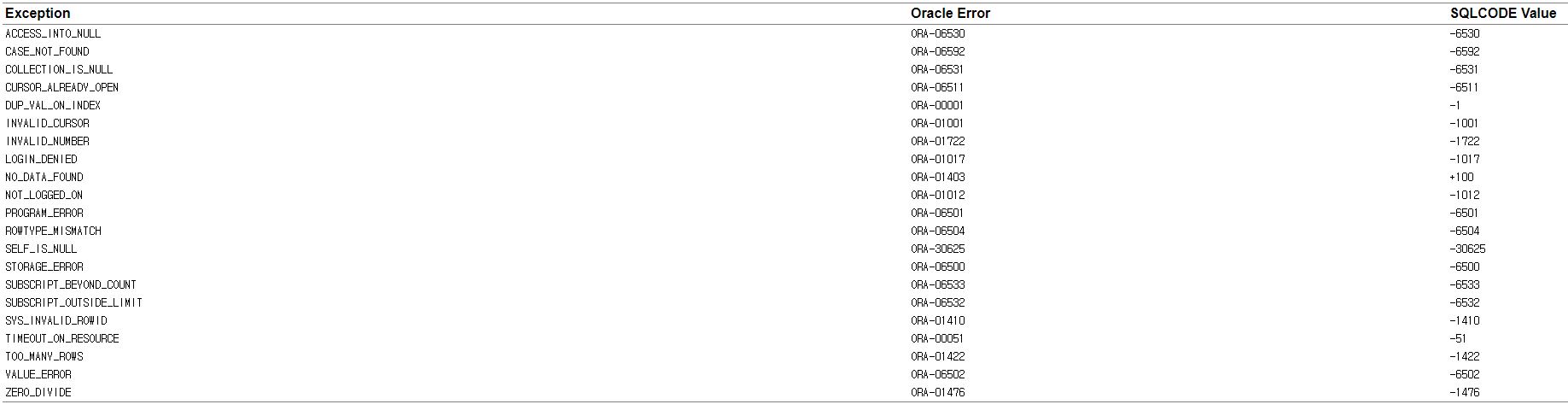
만약 최대요수 개수보다 많은 요소를 선언하려고 하면 ORA-06532 오류가 터진다.
1 2 3 4 5 6 7 8
오류 보고 - ORA-06532: Subscript outside of limit ORA-06512: at line 1 06532. 00000 - "Subscript outside of limit" *Cause: A subscript was greater than the limit of a varray or non-positive for a varray or nested table. *Action: Check the program logic and increase the varray limit if necessary.
사용 예시를 보면 다음과 같다. 먼저 연관배열과 다르게 생성자로 VARRY 가변 길이 배열을 초기화하고 , 변수명(인덱스) 형태로 값을 조회 또는 값을 저장 할 수 있다.
DECLARE -- 5개의 문자형 값으로 이루진 VARRAY 선언 TYPE va_type IS VARRAY(5) OF VARCHAR2(20); -- VARRY 변수 선언 vva_test va_type; vn_cnt NUMBER :=0; BEGIN -- 생성자를 통해 VARRAY 가변 배열 초기화 vva_test := va_type('FIRST' , 'SECOND' , 'THIRD' ,'' ,''); -- 나머지 4,5번째 INDEX값은 NULL값이 된다. LOOP vn_cnt := vn_cnt+1; IF vn_cnt >5THEN EXIT; END IF; -- VARRAY 요소에 접근할때는 VARRAY변수명(인덱스) 로 가능하다. DBMS_OUTPUT.PUT_LINE(vva_test(vn_cnt)); END LOOP; vva_test(1) :='FIRST VALUE CHANGED'; DBMS_OUTPUT.PUT_LINE(vva_test(1)); END;
중첩 테이블 (Nested Table)
요소 제한이 없으나 , 숫자형 인덱스만 사용 가능하다.
생성자를 사용하며 , 일반 테이블의 칼럼 타입으로 사용될 수 있다.
중첩 테이블 선언 문법
1
TYPE 중첩테이블명 IS TABLE OF 값타입;
1 2 3 4 5 6 7 8 9 10 11
DECLARE -- 중첩 테이블 선언 TYPE nt_type ISTABLEOF VARCHAR2(10); -- 중첩 테이블 변수 선언 vnt_test nt_type; BEGIN -- 중첩 테이블 생성자 사용 vnt_test := nt_type('FIRST','SECOND','THIRD','ETC'); DBMS_OUTPUT.PUT_LINE(vnt_test(4)); END;
레코드에서는 레코드를 이루고 있는 각 칼럼을 필드라고 부른다. 테이블과 유사하게 생겼지만 , 하나의 row만을 가질 수 있다.
1 2 3 4
TYPE 레코드명 IS RECORD ( 필드명 필드타입 [NOTNULL] [:= 디폴트값], 필드명 필드타입 [NOTNULL] [:= 디폴트값], )
실제 Record 타입을 선언하는 예시를 보면 다음과 같다. 이때 필드타입으로 %TYPE 문법을 사용할 수도 있다.
1 2 3 4 5 6 7 8 9 10 11 12
DECLARE -- 특정 레코드 타입 선언 TYPE depart_rect IS RECORD ( department_id NUMBER(6), --department_id departments.department_id%TYPE department_name VARCHAR2(80), parent_id NUMBER(6), manager_id NUMBER(6) ); -- 레코드 타입의 변수 선언 vr_dep depart_rect; BEGIN END;
DECLARE -- 특정 레코드 타입 선언 TYPE depart_rect IS RECORD ( department_id departments.department_id%TYPE, department_name departments.department_name%TYPE, parent_id departments.parent_id%TYPE, manager_id departments.manager_id%TYPE ); -- 레코드 타입의 변수 선언 vr_dep depart_rect; vr_dep2 depart_rect; BEGIN -- 레코드 타입의 필드에 접근할때는 레코드타입변수.필드명으로 접근한다. vr_dep.department_id :=999; vr_dep.department_name :='test department'; vr_dep.parent_id :=100; vr_dep.manager_id :=NULL; -- 레코드 타입 변수는 동일한 타입이면 다른 변수에 할당이 가능하다. vr_dep2 := vr_dep;
END;
Record 타입 변수를 활용해 테이블에 INSERT 또는 UPDATE할 수 있다. 이떄 전제조건은 당연히 테이블의 칼럼 개수 , 타입과 레코드의 필드의 칼럼 개수, 타입이 동일해야한다.
CREATETABLE dep AS SELECT department_id , department_name , parent_id , manager_id FROM DEPARTMENTS;
DECLARE -- 특정 레코드 타입 선언 TYPE depart_rect IS RECORD ( department_id departments.department_id%TYPE, department_name departments.department_name%TYPE, parent_id departments.parent_id%TYPE, manager_id departments.manager_id%TYPE ); -- 레코드 타입의 변수 선언 vr_dep depart_rect; BEGIN -- 레코드 필드 값 초기화 -- 테이블에 레코드 타입으로 값 insert INSERTINTO dep values vr_dep; END;
특정 SQL 문장을 처리한 결과를 담고 있는 영역 (PRIVATE SQL이라는 메모리 영역) 을 가르키는 일종의 포인터이다.
커서를 통해 처리된 SQL 문장의 결과 집합에 접근할 수 있다. 개별 로우에 순차적으로 접근하는 형태이다.
커서의 종류에는 묵시적 커서와 명시적 커서가 있는데, 묵시적 커서는 oracle 내부적으로 자동으로 생성되어 사용하는 커서이다. PL/SQL 블록에서 실행하는 SQL 문장이 실행될 때마다 자동으로 만들어져 사용된다. 명시적 커서는 개발자가 직접 정의해서 사용하는 커서를 뜻한다.
커서의 종류와 무관하게 Cursor의 라이프사이클은 open -> fetch -> close 3단계로 나누어 진행된다.
묵시적 Cursor
개발자가 Cursor의 동작에 관여할 수는 없지만, Cursor의 정보를 참조할 수는 있다.
1 2 3 4 5 6 7 8 9 10 11
SET SERVEROUTPUT ON; DECLARE vn_department_id employees.department_id%TYPE :=80; BEGIN UPDATE employees SET emp_name = emp_name WHERE department_id = vn_department_id; DBMS_OUTPUT.PUT_LINE(SQL%ROWCOUNT); --SQL 커서의 ROWCOUNT 속성 COMMIT; END;
위 예제에서 보면 SQL 커서를 어디에도 선언하진 않았지만, 커서의 정보를 참조할 수는 있다. 기타 커서의 속성들은 다음과 같다.
SQL%FOUND : 결과 집합의 행수가 1개 이상이면 TRUE 아니면 FALSE를 반환
SQL%NOTFOUND : 결과 집합의 행수가 0개이면 TRUE 아니면 FALSE를 반환
SQL%ROWCOUNT : 영향 받은 결과 집합의 행수를 반환 , 없으면 0을 반환
명시적 Cursor
Cursor 선언
1 2 3
CURSOR 커서명 (매개변수) IS SELECT 문장;
명시적 커서 선언은 위와 같이 가능하다. 이때 매개변수는 생략이 가능한데, 매개변수의 주 사용 목적은 SELECT Query의 WHERE 절에 들어갈 조건으로 사용된다고 한다.
CREATE OR REPLACE FUNCTION 함수 이름 (매개변수1,매개변수2, ...) RETURN 데이터타입; IS[AS] 변수 선언 BEGIN 실행부 RETURN 반환값; [EXCEPTION 예외 처리부] END [함수 이름];
사용자 정의 함수 예시
1 2 3 4 5 6 7 8 9 10 11
CREATEOR REPLACE FUNCTION my_mod (num1 NUMBER , num2 NUMBER ) RETURN NUMBER IS vn_remainder NUMBER:=0; --나머지 vn_quotient NUMBER:=0; --몫; BEGIN vn_quotient :=FLOOR(num1/num2); vn_remainder := num1 - (num2*vn_quotient); RETURN vn_remainder; END;
정의한 사용자 정의 함수를 사용할떄는 SELECT 절 또는 PL/SQL 블록 내에서 사용 가능하다. 다음은 SELECT 절에서 사용하는 예시이다.
1 2
SELECT my_mod(10,3) reminder FROM DUAL;
프로시저 (Procedure)
함수의 경우 특정 연산을 수행한 뒤 값을 반환하지만 프로시저는 로직만 처리하고 값을 반환하지 않는다.
대표적인 사용예시는 테이블에서 데이터를 추출해 처리하고, 결과를 다른 테이블에 저장하거나 갱신하는 등 DML 작업을 수행한다.
기본 단위는 Block 으로 이루어진다. Block은 선언부 , 실행부 , 예외처리부 로 구성되는데, 익명 블록과 이름이 있는 블록 (함수,프로시저,패키지) 로 나뉜다.
1 2 3 4 5 6 7
이름부 ## BLOCK의 명칭이 오는 자리 IS (AS) 선언부 ## DECLARE로 시작되며, 실행부와 예외처리부에서 사용할 변수 정의 BEGIN 실행부 ## 비즈니스 로직 EXCEPTION 예외처리부 ## EXCEPTION 절로 시작되는 부분으로 비즈니스 로직을 처리하다가 오류가 생기면 실행되는 내용
기본구조에서 이름부와 예외처리부는 생략이 가능하며 , 이름부를 생략할 경우에는 익명 블록이라고 한다.
예제를 보면 다음과 같다.
1 2 3 4 5 6 7 8 9
SET SERVEROUT ON; -- 입출력 ON SET TIMING ON; -- PL/SQL 블록 실행시간 출력 DECLARE vi_num NUMBER; --선언부 BEGIN vi_num :=100; -- 실행부 DBMS_OUTPUT.PUT_LINE(vi_num); END;