코틀린의 Null 타입 안정성은 자바에서 빈번하게 볼수 있었던 NPE (Null-Pointer Exception)이 발생할 포인트를 줄여준다.
문제는 코틀린과 다른 프로그래밍 언어를 연결해서 사용할때이다. 아래와 같이 annotation 으로 nullable 여부를 판단할 수 있다면 정확한 타입을 추정할 수 있다.
1 2 3 4 5
publicclassSample{
@NotNull private String test; }
만약 annotation이 붙어있지 않다면 , Kotlin은 해당 타입을 nullable인지 아닌지 판단할 방법이 없다. 따라서 Kotlin은 해당 타입을 Platform Type으로 간주한다. Platform Type은 타입 이름뒤에 ! 기호를 붙여서 표기한다 (String!)
Platform Type은 코틀린이 Null 관련 정보를 알 수 없기 떄문에, 컴파일러는 Nullable 타입으로 처리하든, 아니든 모든 연산을 허용한다 하지만 개발자에게 전적으로 NPE을 처리할 책임이 넘어간다.
JSR-Annotation
java와 코틀린을 같이 사용할때에는 Java 코드를 만약 직접 변경할 수 있다면, 가능한 @Nullable , @NotNull annotation을 붙이는 게 안전하다.
대표적인 annotation 예시는 다음과 같다.
org.jetbrains.annotation : @Nullable , @NotNull
javax.annotation JSR-305 : @Nullable , @NonNull
Lombok :@NonNull
정리
다른 프로그래밍 언어에서 Nullable 여부를 알 수 없는 타입을 Platform type이라고 하며 , 코틀린 컴파일러는 이에 대한 연산을 제약하진 않는다. 다만, 개발자가 전적으로 NPE을 핸들링 해야 한다, 따라서 Platform Type을 지양하고, 자바 쪽에서 수정이 가능하다면 Annotation 을 붙이자.
최대한 변수의 사용 스코프를 줄이는게 좋다. 예를 들어 변수가 반복문안에서만 사용된다면, 변수를 반복문 블록 내부에 작성하는 게 좋다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// 1 var user : User for( i in users.indices){ user = users[i] println("user at $i is $user") } // 2 for(i in users.indices){ val user = users[i] println("user at $i is $user") } // 3 for((i,user) in users.withIndex()){ println("user at $i is $user") }
1번예는 user를 반복문 블록 외부에서도 사용 가능하다. 반면 2,3번 예에서는 user의 스코프 블록을 for 반복문 내부로 제한한다.
2번,3번예는 변수를 반복문 내부로 감추고, 3번예의 경우에는 구조 분해 선언을 통해 변수를 초기화하고 있다. 이렇게 변수의 스코프를 좁게 만듦으로서 갖는 장점은 프로그램 변경 요소를 줄여, 이해하기 쉽고 디버깅이 쉽게 만든다.
반대로 변수의 스코프 범위가 너무 넓으면 다른 개발자에 의해 변수가 잘못 사용될 가능성이 있다. 따라서 변수는 정의할때 초기화되는게 가장 좋다.
1 2 3 4 5 6 7 8 9 10 11 12 13
//1 val user:User if(hasValue){ user = getValue() } else{ user = User(); } //2 val user:User = if(hasValue){ getValue() }else { User() }
위 코드에서처럼 2번과 같이 선언과 동시에 초기화하는것이 좋다. 만약 여러 프로펕치를 한꺼번에 설정해야 한다면 구조분해 선언을 활용하는게 좋다.
1 2 3 4 5 6 7
fun updateWeather(degrees: Int){ val(description, color) = when{ degrees <5 -> "cold" to Color.BLUE degrees >23 -> "mild" to Color.YELLOW else -> "hot" to Color.RED } }
클래스,프로퍼티와 같은 요소가 var 또는 mutable 객체를 사용하면 상태를 가질 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classBankAccount{ // 가변 상태 var balance = 0.0 private set fun deposit(depositAmount :Double){ balance += depositAmount } @Throws(InsufficientFunds::class) fun withdraw(widthdrawAmount : Double){ if (balance < widthdrawAmount){ throw InsufficientFunds() } balance -= widthdrawAmount } }
classInsufficientFunds :Exception()
위처럼 BankAccount 클래스는 잔액을 나타내는 변화할 수 있는 상태가 있다, 변화할 수 있는 상태를 가지는 요소는 다음과 같은 단점을 가진다.
프로그램을 이해하고 디버깅하기 힘들어진다. 오류시 상태 변경을 추적해야 한다.
멀티쓰레드 환경에서 동기화가 필요하다
테스트가 어렵다. 모든 상태에 대해서 테스트를 염두해두어야 한다.
상태변경에 따른 추가적인 조치가 필요할수도 있다. 예를 들면 항상 정렬된 경우로 유지되야할경우 값이 추가되었을떄 정렬작업이 필요하다.
반면 불변성을 유지하였을때 갖는 장점은 다음과 같다.
한번 객체의 상태가 정의되고 나서 변경되지 않으므로, 코드 이해가 쉽다.
병렬 처리에 안전
방어적 복사본을 만들지 않아도 된다.
Set,Map의 Key로 사용이 가능하다. 요소의 값이 변경되지 않기 때문이다.
멀티쓰레드환경에서 쓰레드간 공유되는 변수의 값을 변경할때 가변상태를 가지는 경우 값이 부정확하게 나올 수도 있다.
1 2 3 4 5 6 7 8 9 10 11
fun main(){ var num = 0 for (i in 1..1000){ thread { Thread.sleep(10) num+=1 } } Thread.sleep(5000) println(num) }
위 연산은 매번 실행할떄마다 공유변수에 값을 여러 쓰레드에서 변경함으로 , 연산이 덮어씌워지는 경우가 생겨 다른 값이 나온다. 이를 동기화하려면 아래와 같이 공유변수에 Lock을 걸어서, 접근을 제한하고 순차적으로 값을 증가시켜야 한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
fun main(){ var lock = Any() var num = 0 for (i in 1..1000){ thread { Thread.sleep(10) synchronized(lock){ /*Lock을 획득하고 공유변수에 접근가능하도록 동기화*/ num+=1 } } } Thread.sleep(5000) println(num) }
Kotlin에서 가변성을 제한하는 방법
Kotlin은 언어차원에서 가변성을 제한할수 있는 방법을 설계하였다.
val
Kotlin은 읽기 전용 프로퍼티 (val)을 사용하여, 변수에 재할당이 불가능하도록 만들 수 있다 (java의 final과 유사) 사실 val을 사용한다고 해서 불변성이 보장되는 것은 절대 아니고, 단지 재할당이 불가능하게 setter를 금지한다.
1 2
val x = mutableListOf(1,2,3)\ x.add(4) // 가변
부가적인 내용인데, val는 var로 overriding 이 가능하다.
1 2 3 4 5 6 7
interfaceElement{ val active : Boolean }
classActualElement : Element{ override var active: Boolean = false }
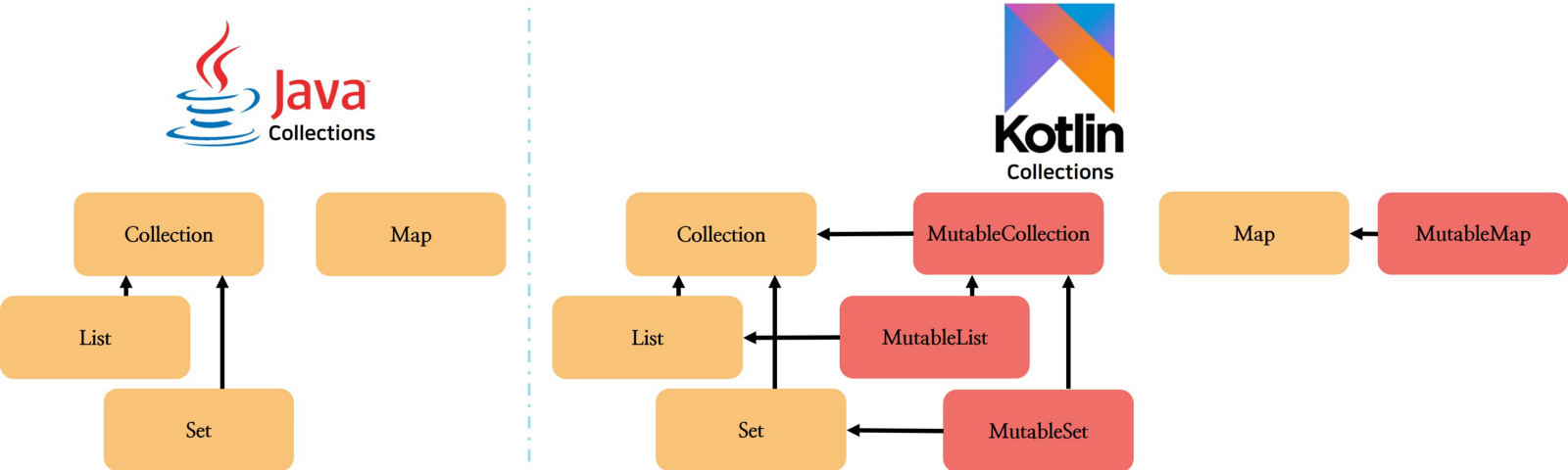
가변 Collection과 읽기 전용 Collection (read-only)
Kotlin은 Collection을 MutableCollection과 읽기 전용인 Collection으로 구분한다.
Kotlin은 Collection , Set ,List를 기본적으로는 읽기 전용으로 내부의 상태를 변경하기 위한 method를 제공하지 않는다. MutableCollection , MutableSet , MutableList 인터페이스는 읽기 전용 인터페이스를 상속받아서, 추가적으로 변경을 위한 method를 붙였다.
주의해야할점은 읽기 전용 Collection 을 가변 Collection으로 downcasting하면 안된다는 점이다.
1 2 3 4
val list = listOf(1,2,3) if (list is MutableList){ list.add(4) // java.lang.UnsupportedOperationException 예외 발생 }
Jvm에서 listOf는 Java의 List 인터페이스를 구현한 Array.ArrayList 객체를 반환하는데 이는 add,set 을 모두 가지고 있기에 MutableList로 다운캐스팅이 된다. 하지만 Arrays.ArrayList 객체는 이러한 연산을 구현하고 있지 않기 떄문에 위와 같이 UnsupportedOperationException이 터진다.
읽기 전용 Collection에서 MutableCollection으로 꼭 변경해야 한다면 , copy를 사용해서 변경해야 한다.
1 2 3 4
fun main(){ val list = listOf(1,2,3) list.toMutableList(); // 새로운 객체 반환 }
이렇게 구현하면 기존 객체는 새로 반환된 객체에 영향받지 않고 수정이 가능하다.
Data Class의 Copy
immutable 객체는 자기 자신의 상태가 일부 다른 경우에도 새로운 객체를 만들어야 되기 때문에, 자신의 일부를 수정해서 새로운 객체를 만들어 줄 수 있는 method를 가져야 한다.
이떄 data 한정자를 붙이면 자동으로 copy method를 만들어주는데, copy method는 모든 기본생성자 프로퍼티가 동일한 새로운 객체를 만들어 낼 수 있다. 따라서 원래의 불변객체가 존재하는데, 특정 상태만 바꾼 새로운 객체를 만들어내고 싶다면 copy method를 활용하면 된다.
1 2 3 4 5 6 7
data class Account(val money:Int,val owner:String) fun main(){ val myPoorAccount = Account(10000,"김찬수") val myHappyAccount = myPoorAccount.copy(money = 1000_000_000); println(myHappyAccount) }
비선점형 (협력형) 멀티 태스킹 (non-preemptive multitasking)으로 실행을 일시 중단(suspend) 하고 재개(resume) 할 수 있는 여러 진입 지점을 허용한다.
서로 협력해서 실행을 주고받으면서 작동하는 여러 서브루틴을 말한다.
일반적인 서브루틴은 오직 한 가지 진입 지점만을 가진다. 함수를 호출하는 부분이며, 그때마다 활성 레코드 (activation record)가 스택에 할당되면서 서브루틴 내부의 로컬 변수등이 초기화 된다. 또한 서브루틴에서 반환되고 나면 활성 레코드가 스택에서 사라지기 떄문에 모든 상태를 잃어버린다.
1 2 3 4 5 6 7 8 9
fun main(){ //main routine val extension = getFileExtension("cs.txt") }
fun getFileExtension(fileName:String) :String{ // subroutine return fileName.substringAfter(".") }
fun log(msg:String , self : Any?)= println("Current Thread : ${Thread.currentThread().name} / this : $self :$msg")
fun main(){ log("main routine started",null) yieldExample() log("main routine ended",null) }
fun yieldExample(){ runBlocking{ //내부 코루틴이 모두 끝난뒤 반환 launch { log("1",this) yield() // log("3",this) yield() log("5",this) } log("after first launch",this) launch { log("2",this) yield() log("4",this) yield() log("6",this) } log("after second launch",this) }
}
실행로그
1 2 3 4 5 6 7 8 9 10
Current Thread : main / this : null :main routine started Current Thread : main / this : BlockingCoroutine{Active}@33e5ccce :after first launch Current Thread : main / this : BlockingCoroutine{Active}@33e5ccce :after second launch Current Thread : main / this : StandaloneCoroutine{Active}@2ac1fdc4 :1 Current Thread : main / this : StandaloneCoroutine{Active}@3ecf72fd :2 Current Thread : main / this : StandaloneCoroutine{Active}@2ac1fdc4 :3 Current Thread : main / this : StandaloneCoroutine{Active}@3ecf72fd :4 Current Thread : main / this : StandaloneCoroutine{Active}@2ac1fdc4 :5 Current Thread : main / this : StandaloneCoroutine{Active}@3ecf72fd :6 Current Thread : main / this : null :main routine ended
위 코드를 분석하기 전에 각각 함수가 하는 역할을 정리하면 다음과 같다.
runBlocking : coroutine builder 로서 내부 코르틴이 모두 끝난 다음에 반환된다.
launch : coroutine builder로서 , 넘겨받은 코드 블록으로 새로운 코르틴을 생성하고 실행시켜준다.
yield : 해당 코르틴이 실행권을 양보하고, 실행 위치를 기억하고, 다음 호출때는 해당 위치부터 다시 실행한다.
위 코르틴에서 1,3,5를 출력하는 코르틴과 2,4,6를 출력하는 코르틴이 서로 실행권을 양보해가면서 실행된다. 한가지 유의할점은 마치 병렬적으로 실행되는 것처럼 보이지만 다른 쓰레드가 아니라 하나의 쓰레드에서 수행된다는 점이다. 따라서 Context Switching 도 발생하지 않는다.
Launch coroutine Builder는 Job 객체를 반환한다. Job은 N개 이상의 coroutines의 동작을 제어할 수도 있으며, 하나의 coroutines 동작을 제어할수도 있다.
1 2 3 4 5 6 7 8 9 10
suspend fun main()= coroutineScope { // Job 객체는 하나이상의 Coroutine 의 동작을 제어할 수 있다. val job : Job = launch { delay(1000L) println("World!") } println("Hello,") job.join() println("Done.") }
Async는 사실상 Launch와 같은일을 수행하는데, 차이점은 Launch는 Job객체를 반환하는 반면 , Async는 Deffered를 반환한다.
1 2 3 4 5 6 7 8 9 10 11 12 13
publicinterfaceDeferred<outT> : Job{
public suspend fun await(): T public val onAwait: SelectClause1<T> @ExperimentalCoroutinesApi public fun getCompleted(): T @ExperimentalCoroutinesApi public fun getCompletionExceptionOrNull(): Throwable? }
Deffered는 Job을 상속한 클래스로서, 타입 파라미터가 있는 제너릭 타입이며, Job과 다르게 await 함수가 정의되어 있다.
Deffered의 타입 파라미터는 Deffered 코루틴이 계산 후 돌려주는 값의 타입이다. 즉 Job은 Deffered<Unit>라고 생각할수도 있다.
정리하면 async는 코드 블록을 비동기로 실행 할 수 있고, async가 반환하는 Deffered의 await를 사용해서 코루틴이 결과 값을 내놓을떄까지 기다렸다가 결과값을 받아올 수 있다.
이떄 비동기로 실행할떄 제공되는 코루틴 컨텍스트에 따라 하나의 Thread안에서 제어만 왔다 갔다 할수도 있고, 여러 Thread를 사용할 수도 있다.
1 2 3 4 5 6 7 8 9 10 11
fun sumAll(){ runBlocking { val d1 = async { delay(1000L); 1 } println("after d1") val d2 = async { delay(2000L); 2 } println("after d2") val d3 = async { delay(3000L); 3 } println("after d3") println("1+2+3 = ${d1.await()+d2.await()+d3.await()}") } }
실행로그를 보면 다음과 같다.
1 2 3 4
after d1 after d2 after d3 1+2+3 = 6 // 코루틴이 결과값을 내놓을떄까지 기다렸다가 결과값을 받아온다.
만약 위 코드를 직렬화해서 실행하면 최소 6초의 시간이 걸리겠지만, async로 비동기적으로 실행하면 3초가량이 걸리며 더군다나 위 코드는 별개의 thread가 아니라 main thread 단일 thread로 실행되어 이와 같은 성능상 이점을 얻을수 있다.
특히 이와 같은 상황에서 코루틴이 장점을 가지는 부분은 I/O로 인한 장시간 대기 , CPU 코어수가 작아 동시에 병렬적으로 실행 가능한 쓰레드 개수 한정된 상황 이다.
코루틴 컨텍스트
Launch , Async 등은 모두 CoroutineScope의 확장함수로 실제로 CoroutineScope는 CoroutineContext 필드를 이런 확장함수 내부에서 사용하기 위한 매개체 역할을 수행한다. 원한다면 launch,aync 확장함수에 CoroutineContext를 넘길수도 있다.
/** * Launches a new coroutine without blocking the current thread and returns a reference to the coroutine as a [Job]. * The coroutine is cancelled when the resulting job is [cancelled][Job.cancel]. * * The coroutine context is inherited from a [CoroutineScope]. Additional context elements can be specified with [context] argument. * If the context does not have any dispatcher nor any other [ContinuationInterceptor], then [Dispatchers.Default] is used. * The parent job is inherited from a [CoroutineScope] as well, but it can also be overridden * with a corresponding [context] element. * * By default, the coroutine is immediately scheduled for execution. * Other start options can be specified via `start` parameter. See [CoroutineStart] for details. **/ public fun CoroutineScope.launch( context: CoroutineContext = EmptyCoroutineContext, start: CoroutineStart = CoroutineStart.DEFAULT, block: suspend CoroutineScope.() -> Unit ): Job { //... }
// --------------- async ---------------
/** * Creates a coroutine and returns its future result as an implementation of [Deferred]. * The running coroutine is cancelled when the resulting deferred is [cancelled][Job.cancel]. * The resulting coroutine has a key difference compared with similar primitives in other languages * and frameworks: it cancels the parent job (or outer scope) on failure to enforce *structured concurrency* paradigm. * To change that behaviour, supervising parent ([SupervisorJob] or [supervisorScope]) can be used. * * Coroutine context is inherited from a [CoroutineScope], additional context elements can be specified with [context] argument. * If the context does not have any dispatcher nor any other [ContinuationInterceptor], then [Dispatchers.Default] is used. * The parent job is inherited from a [CoroutineScope] as well, but it can also be overridden * with corresponding [context] element. * * By default, the coroutine is immediately scheduled for execution. * Other options can be specified via `start` parameter. See [CoroutineStart] for details. * */ public fun <T> CoroutineScope.async( context: CoroutineContext = EmptyCoroutineContext, start: CoroutineStart = CoroutineStart.DEFAULT, block: suspend CoroutineScope.() -> T ): Deferred<T> { //... }
그렇다면 CoroutineContext가 하는 역할은 무엇일까?
코루틴이 실행중인 여러 작업과 디스패처를 저장하는 일종의 맵으로 이 CoroutineContext를 사용해 다음에 실행할 작업을 선정하고, 어떻게 Thread에 배정할지에 대한 방법을 결정한다.
fun context(){ runBlocking { launch { // 부모 컨텍스트를 사용 println("use parent context :${getThreadName()}") } launch(Dispatchers.Unconfined) { // 특정 Thread에 종속되지 않고, Main Thread 를 사용 println("use main thread :${getThreadName()}") } launch(Dispatchers.Default){ println("use default dispatcher :${getThreadName()}") } launch(newSingleThreadContext("MyOwnThread")){ // 직접 만든 새로운 Thread 사용 println("use thread that i created : ${getThreadName()}") } } }
실행로그를 보면 같은 launch 확장함수를 사용한다고 하더라도 실행되는 CoroutineContext에 따라 다른 Thread상에서 코루틴이 실행됨을 확인할 수 있다.
1 2 3 4
use main thread :main use default dispatcher :DefaultDispatcher-worker-1 use parent context :main use thread that i created : MyOwnThread
Coroutine Builder 와 Suspending Function
앞선 Launch , Async , runBlocking , CoroutineScope모두 코루틴 빌더라고 , 새로운 코루틴을 만들어주는 함수이다.
delay , yield 함수는 일시중단 함수로 이외에도 다른 일시중단 함수들이 존재한다.
Java와 다르게 Kotlin에서는 람다안에서 return 을 사용하면 람다로부터만 반환되는게 아니라, 그 람다를 호출하는 함수가 실행을 끝내고 반환된다.
이를 Non-Local Return 이라고 부른다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// java List.of("a","b","c").forEach((item)-> { if (item.equals("a")){ return; } // b,c에 대해서도 실행됨. }); // kotlin listOf("a","b","c").forEach { if (it.equals("a")){ return; } println(it) // a에서 종료됨 }
Non-Local Return 이 적용되는 상황
람다 안의 return 문이 바깥쪽 블록의 함수를 반환시킬 수 있는 상황은 람다를 인자로 받는 함수가 인라인 함수인 경우에만 가능하다. 즉 위의 forEach 함수는 인라인이기에 Non-local return 이 가능한 것이다.
Label을 사용한 Local return
람다식안에서 람다의 실행을 끝내고 람다를 호출했던 코드의 실행을 이어서 실행하기 위해서는 Local Return을 사용하면 된다.
Non-Local Return 과 구분하기 위해서 Local Return에는 레이블을 추가해야 한다.
1 2 3 4 5 6 7 8 9 10
fun lookForBob(people : List<Person>){ people.forEach label@{ if (it.name == "Bob"){ println("found Bob!") return@label } } // Local Return을 사용하면 람다가 종료되고 람다 아래의 코드가 실행된다. println("end of function") }
또는 인라인 함수의 이름을 label로 사용하여도 위의 코드와 동일하다.
1 2 3 4 5 6 7 8 9 10
fun lookForBob(people : List<Person>){ people.forEach { if (it.name == "Bob"){ println("found Bob!") return@forEach } } println("end of function") }
Anonymous Function 을 사용한 깔끔한 Local Return
앞선 Local Return 방식은 레이블을 통해 구현하여, 조건 분기에 따라 여러번 Return 문을 기입해야 할떄는 반환문이 장황해 질 수 있다.
Anonymous Function은 (익명,무명함수) 코드 블록을 함수에 넘길때 사용할 수 있는 방법 중에 하나로 일반 함수와 차이점은 함수 이름과 파라미터 타입을 생략 가능하다는 점이다.
1 2 3 4 5 6 7 8 9
fun lookForBob(people : List<Person>){ people.forEach (fun(person){ if (person.name == "Bob"){ println("found Bob!") return } println("end of anonymous function") })
기본적으로 익명함수도 반환타입을 기입해줘야 하지만, 함수 표현식 (expression body)를 바로 쓰는 경우에는 반환타입 생략이 가능하다.
정리
Inline 함수의 경우 람다안의 return문이 바깥쪽 block의 함수를 반환시키는 Non-Local Return을 사용할 수 있다.
Anonymous Function을 활용하면 람다를 대체해서 Local Return을 깔끔하게 Label 사용없이 작성 가능하다.