연결 성분 (Connected Component) : 그래프에서 정점들이 서로 연결되어 있는 부분
가중치 그래프 (Weighted Graph) : 간선에 가중치가 부여된 그래프
신장트리 (Spanning Tree) : 그래프가 하나의 연결성분으로 구성되어 있을 때, 그래프의 모든 정점들을 cycle없이 연결하는 부분 그래프
그래프 구현 방법
그래프를 구현하기 위한 방법으로 2가지가 존재한다.
인접행렬 (Adajacent Matrix) : 2차원 배열로 표현하는 방법으로 n개의 정점이 존재한다고 하였을 떄 , n x n 배열로 표현하여 그래프의 정점 i 와 정점 j 간에 연결선이 존재하면 1을 표시하고, 연결선이 존재하지 않으면 0을 표시하여 구성한다. dense graph를 표현할떄 유리하다.
장점 : 정점간의 연결선 여부를 O(1) 으로 파악 가능
단점 : O(N^2)의 공간 복잡도를 가짐
인접 리스트 (Adjacency List) : 정점과 해당 정점에 인접한 정점들을 연결리스트로 표현하는 방식으로, n개의 정점이 존재한다고 하였을떄, n x n 연결리스트로 구성된다. sparse graph를 표현할떄 유리하다.
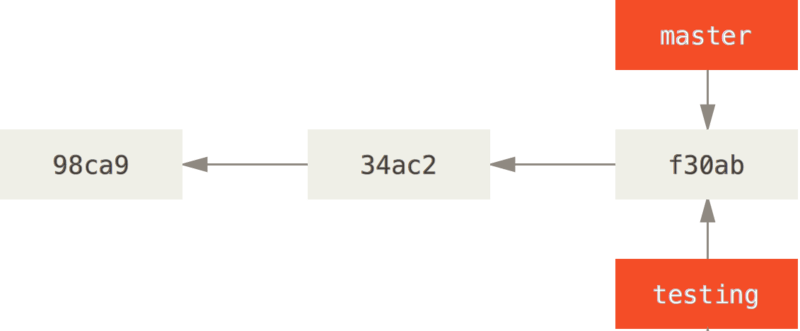
그럼 두 branch중에 현재 working directory에서 작업중인 branch를 어떻게 나눌까?
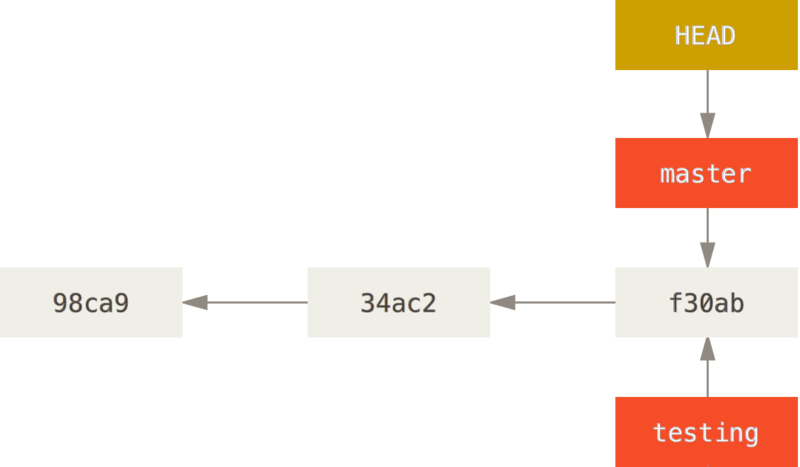
Git은 HEAD라고 하는 로컬 Branch를 가르키는 특수한 pointer가 존재한다.
1 2 3
C:\Users\katd6\OneDrive\바탕 화면\hello-git>git branch -a * master testbranch
branch 이동하기
git checkout <이동할 branch명>
git branch 는 checkout 명령어로 이동할 수 있다. 아까 정리했던것처럼 Git은 HEAD라고 하는 현재 작업중인 Local branch를 가르키는 pointer인 HEAD가 존재한다고 하였다. git checkout 명령어로 로컬 branch를 바꾼다는 것은 결국에 이 pointer가 가르키는 branch를 변경하겠다는 말이랑 동일하다.
형상관리(버전관리)를 하기 위한 tool로써 소스코드를 효과적으로 관리하기 위해 개발된 분산형 버전 관리 시스템이다. 형상관리를 하기 위한 또다른 대표적인 tool로 SVN (subversion)이 존재한다. SVN은 Git은 분산형 버전 관리 시스템임에 비해 중앙집중관리식이다. 즉 local PC에서 commit을 하면 바로 중앙저장소에 반영되는 반면에 Git은 각 개발자마다 로컬저장소가 있어, push 전에는 중앙저장소에 반영되지 않는다.
Git Repository : Git repository는 변경 이력별로 구분되어 소스코드가 저장되는데, 원격 저장소, 로컬 저장소로 나뉜다.
Remote Repository (원격 저장소) : 파일이 원격 저장소 서버에 저장되며 , 협업하는 개발자들과 공유 가능
Local Repository (로컬 저장소) : 말 그대로 로컬 PC에 파일이 저장되며 개인 저장소이다.
Git은 로컬저장소가 있음으로 성능상에 SVN에 비해 얻을 수 있는 장점도 있다. 프로젝트의 history를 조회하거나 어떤 파일의 현재 버전과 한달전 버전을 비교하고자 할떄 네트워크 요청없이 수행될 수도 있다.
Git 파일 상태
Git은 파일을 Committed , Modified , Staged 이렇게 3가지 상태로 관리한다.
Committed : data 가 local repository에 안전하게 저장되었음 (git commit 이후 상태 )
Modified : data 가 수정되었으나 local repository 에 저장되지 않았음
Staged : 현재 수정한 file을 곧 commit 할것이라고 표시한 상태 (git add 이후 상태)
Transaction은 작업의 논리적인 단위로서 , 예를 들면 은행에서 출금 후 입금을 한다고 가정하였을떄 실제로 DB query문은 여러 번 나가겠지만 하나의 논리적인 작업 단위로 볼 수 있다. Transaction이 필요한 이유는 데이터베이스 연산 중간에 일관되지 않은 상태가 존재하기 떄문이다. 2개의 연산중에 하나만 수행되고 하나는 아직 수행되지 않은 상태가 존재할 수도 있다. 따라서 데이터베이스는 작업의 완전성을 보장해주기 위해서 , 일련의 연산들을 사용자 입장에서 마치 단일 연산인것처럼 보이게 해준다.
추가로 transaction은 다음과 같은 특징을 갖는다.
Transaction은 recovery 단위이다. 실제로 DB에 쓰여지는 과정에서 system failure시 write ahead log (WAL) 라고 하는데 log라는 자료구조에 먼저 transaction을 쓰고나서 commit처리를 해준다. 즉 commit 이후에 system failure시에는 이 log를 보고 복구가 가능하다.
아래에 Transaction 특성 중에 Isolation (독립성) 이 있다. 서로 다른 transaction은 독립적으로 수행될 수 있어야 하는데 , 이를 위해서는 concurrency control (동시성 제어) mechanism 이 필요하다.
Transaction의 특성 (ACID)
Transaciton 은 작업의 완전성을 보장하기 위해서 다음과 같은 4개의 특성을 갖는다.
Atomicity (원자성): 원자성을 가지므로, 전부 실행되거나 (commit) 혹은 전부 실행되지 않는다 (rollback)
Consistency(일관성) : Transaction은 데이터베이스의 일관성을 유지해야 한다. 즉 일관된 상태에서 일관된 상태로 변환해야 한다.
Isolation(독립성): Transaction은 서로 독립적으로 수행될 수 있어야 한다.
Durability(지속성) : Transaction이 commit되면 DB에 영구적으로 저장되야 한다.
Transaction 상태
transaction은 다음과 같은 상태를 가진다.
Active state : transaction이 아직 실행중인 상태
Partially committed state : transaction의 마지막 연산까지 전부 수행되었지만 commit 하기전의 상태
Failed : transaction중 오류가 발생해 중단된 상태
committed : transaction이 성공적으로 종료되어서 DB에 영구적으로 반영된 상태
aborted : transaction이 비정상적으로 종료되어서 rollback 연산을 통해서 작업을 취소하여 transaction 수행 이전의 일관된 DB 상태로 돌아간 상태
transaction의 병행수행 제어 기법 (concurrency control mechanism )
다른말로 동시성 제어인데, 여러가지 transaction 이 공유자원 (DB 데이터)를 동시에 접근할떄 여러가지 문제가 발생할 수 있다
대표적으로 다음과 같은 문제가 생길 수 있다
lost update problem(갱신 분실 문제) : transaction A 가 수행한 update가 transaction B가 수행한 update를 덮어씌움.
uncommitted dependency problem (비완료 의존성 문제) : transaction A 가 완료되지 않은 상태에서 갱신한 데이터를 transaction B 가 갱신했는데, transaction A가 rollback됨.
package java.lang.annotation; publicenumRetentionPolicy{ /** * Annotations are to be discarded by the compiler. */ SOURCE, /** * Annotations are to be recorded in the class file by the compiler * but need not be retained by the VM at run time. This is the default * behavior. */ CLASS,
/** * Annotations are to be recorded in the class file by the compiler and * retained by the VM at run time, so they may be read reflectively. * * / RUNTIME }
@Override public String toString(){ return name; } }
한가지 방법은 Set 배열에 ordinal method()로 가져온 LifeCycle Enum type의 index 값으로 배열에 indexing 해 저장하는 것이다.
1 2 3 4 5 6 7 8 9 10 11
Set<Plant>[] plantsByLifeCycle = (Set<Plant>[]) new Set[Plant.LifeCycle.values().length]; for(int i = 0 ; i <plantsByLifeCycle.length; i++){ plantsByLifeCycle[i] = new HashSet<>(); } for (Plant p : garden) { plantsByLifeCycle[p.lifeCycle.ordinal()].add(p); }
상수의 위치가 변경될 경우 바로 고장남 (Item 35. ordinal() method는 사용하지 말라고 권고 )
EnumMap
EnumMap을 쓰면 위와 같이 ordinal method로 indexing 하는 단점을 제거해주고, 추가로 출력 문자열도 자체로 제공해준다. EnumMap은 runtime에서 generic type 정보 제공을 위해 생성자에서 key 로 사용할 class 객체를 받는다.
1 2 3 4 5 6 7 8
Map<Plant.LifeCycle, Set<Plant>> plantsByLifeCycle = new EnumMap<>(Plant.LifeCycle.class); for(Plant.LifeCycle lc : Plant.LifeCycle.values()){ plantsByLifeCycle.put(lc,new HashSet<>()); } for (Plant p : garden) { plantsByLifeCycle.get(p.lifeCycle).add(p); } System.out.println("plantsByLifeCycle = " + plantsByLifeCycle);