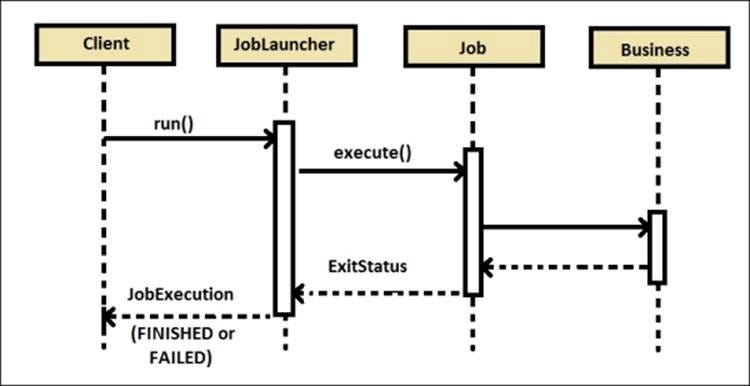
jobLauncher.run(job,jobParameters); // 2. Job Launcher가 주어진 Job과 Job Parameter를 받아서 Job을 실행합니다. } }
Job Instance
Job이 실행될떄 생성되는 Job의 논리적 실행 단위 객체. 즉 작업 실행을 의미한다.
Job과 JobInstance는 왜 구분해야 할까?
Job의 설정과 구성은 동일하지만 Job이 실행되는 시점에 처리하는 내용은 다르기 때문에 Job의 실행을 구분해야 합니다.
JobInstance는 Job과 JobParameter의 조합으로 생성하며, 처음 시작하는 Job과 Job Parameter의 경우는 새로운 Job Instance를 생성합니다.
하나의 Job은 여러번 실행될 수 있으므로 Job과 JobInstance의 연관관계는 1:N의 관계입니다.
BATCH_JOB_INSTANCE 테이블에 매핑됩니다.
Job Runner에 의해 Job 실행시 BATCH_JOB_EXECUTION 테이블
JobInstance의 경우 동일한 Job과 Job Parameter의 조합인 경우 예외(JobInstanceAlreadyCompleteException)를 던집니다.즉 동일한 Job을 동일한 Job Parameter로 돌리면 중복 JobInstance로 판정됩니다.
1 2 3 4 5 6
Caused by: org.springframework.batch.core.repository.JobInstanceAlreadyCompleteException: A job instance already exists and is complete for parameters={name=user1}. If you want to run this job again, change the parameters. at org.springframework.batch.core.repository.support.SimpleJobRepository.createJobExecution(SimpleJobRepository.java:139) ~[spring-batch-core-4.3.9.jar:4.3.9] at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:na] at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:77) ~[na:na] at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:na] at java.base/java.lang.reflect.Method.invoke(Method.java:568) ~[na:na]
Job Parameter
말그대로 Job을 실행할 때 함께 포함되어 사용되는 parameter 가진 도메인 객체입니다
하나의 Job안에 존재하는 여러 JobInstance를 구분하기 위한 용도이다. 즉 JobInstance와 JobParameter는 1:1 관계입니다. (테이블 관계에서는 1:N)
BATCH_JOB_EXECUTION_PARAM 테이블과 매핑됩니다.
Spring Batch에서는 STRING, DATE, LONG, DOUBLE 타입을 지원을 하며, BATCH_JOB_EXECUTION_PARAM 테이블에서 타입별로 칼럼을 가지고 있습니다.
Job Parameter 생성방식
Application 생성 시점에 외부 환경변수로 주입되는 방법
빌드한 Jar파일에 다음과 같이 외부 매개변수로 KEY-VALUE 형태로 값을 주입해줄 수 있다. 이떄 문자형이 아닌 경우는 별도로 (타입명)을 지정해주어야 합니다. 혹은 program argument로 key=value형태로 넣어줄 수 있습니다.
Docker를 구성하는 각각의 파일을 이미지 레이어 라고 부른다. 도커 이미지는 물리적으로는 여러 개의 작은 파일로 구성돼 있다.
하나의 이미지는 위와 같이 여러 이미지가 계층적으로 쌓인 형태로 저장된다. 정리하면 하나의 도커 이미지는 여러개의 이미지 레이어로 구성된다.
도커가 이들 파일을 조립하여 컨테이너 내부 파일 시스템을 만들며 , 전체 이미지를 사용할 수 있게 된다.
Docker 이미지와 이미지 레이어
도커 이미지란 이미지 레이어가 모인 논리적 대상이다.
도커 이미지 레이어란 무엇일까? 아래의 명령어를 입력하면 이미지 레이어에 대한 정보가 출력된다.
1
docker image history web-ping
CREATED BY 칼럼은 해당 이미지 레이어를 구성하는 Dockerfile 스크립트의 명령어이다. 즉 , Dokcerfile의 명령어와 이미지 레이어는 1:1로 매핑된다.
구체적으로 도커 이미지 레이어란 도커 엔진의 캐시에 물리적으로 저장된 파일이다.
이미지 레이어는 여러 이미지와 컨테이너에서 공유된다.
만약 Nodejs 런타임 이미지 레이어를 가진 컨테이너를 여러개 실행하면 이 컨테이너들은 모두 동일한 Nodejs 런타임이 들어 있는 이미지 레이어를 공유한다.
앞서 이미지 레이어는 여러 이미지에서 공유된다고 하였다.
1
docker image ls
상기의 명령어를 입력하면 이미지의 “논리적” 크기를 확인할 수 있는데 , 마치 각각의 이미지가 75.3 MB을 잡아먹는것처럼보인다.
하지만 실제 이미지가 디스크에서 얼마나 차지하는지는 아래의 명령어로 확인이 가능하다. 실제로는 이미지 레이어는 이미지와 컨테이너에서 재사용되기 때문에 150.6MB가 아닌 75.3MB만 디스크에서 공간을 차지하고 있는것을 확인할 수 있다.
1
docker system df
공유 자원 : 이미지 레이어
이미지 레이어는 앞서 정리한대로 여러 이미지에서 공유되는 자원이다. 따라서 공유 자원을 수정하면 이를 사용하고 있는 모든 이미지에게 영향이 갈것이다.
도커는 이미지를 읽기 전용으로 만들어 이런 문제를 방지한다. 즉 이미지 레이어는 수정할 수 없다.
Dockerfile 스크립트 최적화
도커는 캐시에 일치하는 레이어가 있는지 확인하기 위해 해시값을 사용하는데,
Dockerfile의 명령어
Dockerfile의 명령어에 의해 복사되는 파일의 내용 위 2개로부터 계산된다. 즉 명령어가 일치하고 , 파일의 내용 역시 일치한다면 동일한 이미지 레이어 캐시를 사용한다는 말이다. 만약 캐시 미스라면 실제로 Dockerfile의 명령어가 실행되고 , 해당 Dockerfile 스크립트 아래부터는 수정된것이 없다라도 모두 실행된다.
따라서 Dockerfile 스크립트의 명령어는 잘 수정하지 않는 명령어가 앞으로 오고 자주수정되는 명령어는 뒤로 오도록 배치해야지만 캐시된 이미지 레이어를 많이 재사용할 수 있다. 이는 빌드 시간을 줄이고 , 차지하는 디스크 용량 , 또 이미지를 네트워크를 통해 받는다면 네트워크 대역폭까지 줄일 수 있다.
예시
아래의 Dockerfile은 명령어 위치만 변경하더라도 개선할 수 있다. app.js가 자주 수정되는 앱이라고 가정하였을때
@Override public Object invoke(Object proxy, Method method, Object[] args)throws Throwable { String ret = (String) method.invoke(target,args); // 타깃 클래스에게 위임 return ret.toUpperCase(); // 공통 부가 기능 수행 } }
이제 실제로 Dynamic Proxy 를 생성해주는 코드를 보면 Proxy의 정적 팩토리 메소드를 통해 생성할 수 있다.
1 2 3 4 5 6 7
Hello proxy(){ return (Hello) Proxy.newProxyInstance( getClass().getClassLoader(), // 동적으로 생성되는 프록시 클래스 로딩에 사용될 클래스 로더 new Class[]{Hello.class}, // 구현할 인터페이스 new UppercaseHandler(new HelloTarget()) // 부가기능 코드 ); }
Dynamic Proxy의 장점
인터페이스의 메소드가 늘어나도 , 클래스로 직접 구현한 프록시와 다르게 수정이 일어나지 않는다.
부가 기능 코드는 InvocationHandler 구현체에 들어있어서 , 타겟의 종류와 상관없이 적용가능하다. 꼭 특정타입의 타겟이 아니라 , 다른 종류의 타겟에도 적용이 가능하다.
Spring 은 지정된 클래스 이름을 가지고 , Reflection을 통해서 해당 클래스의 객체를 생성한다.
1
Date now = (Date) Class.forName("java.util.Date").newInstance();
반면 Dynamic Proxy 객체 생성 방식은 Proxy 클래스의 newProxyInstance 정적 팩토리 메소드에 의해 생성되며 , 클래스 자체도 런타임에 결정된다. Spring은 어떤 클래스 타입을 해당 Proxy객체가 가질지 , 컴파일 타임에는 알수가 없다.
Factory Bean 을 통해 Dynamic Proxy를 Spring Bean으로 등록한다.
부제 그대로 Spring은 Factory Bean을 통해 Dynamic Proxy 를 Spring Bean으로 등록한다.
Factory Bean이란 Spring을 대신해서 객체의 생성 로직을 담당하도록 만들어진 빈을 말하며 , Spring이 제공해주는 FactoryBean 인터페이스를 구현함으로서 만들 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
package org.springframework.beans.factory;
publicinterfaceFactoryBean<T> {
@Nullable T getObject()throws Exception;
@Nullable Class<?> getObjectType();
defaultbooleanisSingleton(){ returntrue; } }
FactoryBean 인터페이스는 3가지 method로 구성되어있는데 , getObject() method에 Spring Bean으로 등록할 객체 생성로직이 들어가고 , 해당 객체 어떤 클래스 타입인지는 getObjectType() method에 들어간다. isSingleton method는 getObject() method가 반환해주는 객체가 항상 동일한 객체인지 , 즉 싱글톤인지 여부를 명시한다.
아래와 같이 정적 팩토리 메소드를 통해서만 객체 생성을 할 수 있는 경우에 FactoryBean을 활용할 수 있다.
@Override public Message getObject()throws Exception { return Message.newMessage(text); }
@Override public Class<?> getObjectType() { return Message.class; }
@Override publicbooleanisSingleton(){ returnfalse; // Message 정적 팩토리 메소드는 매번 새로운 Message 객체를 // 반환함으로 false로 설정하지만 , 실제로 만들어진 Bean 객체는 싱글톤으로 Spring이 관리해줄 수 있다. } }
Factory Bean 설정
일반 Bean과 다르게 Factory Bean의 경우 bean class property는 FactoryBean 이지만 , 실제로 반환되는 타입은 getObjectType method에 명시된 타입이다. 즉 위 예제에서는 Message 타입이 반환된다.
1 2 3 4
<beanid="message"class="MessageFactoryBean"> <!-- FactoryBean 타입으로 빈 클래스 프로퍼티 설정 --> <constructor-argname="text"value="Factory Bean"></constructor-arg> </bean>
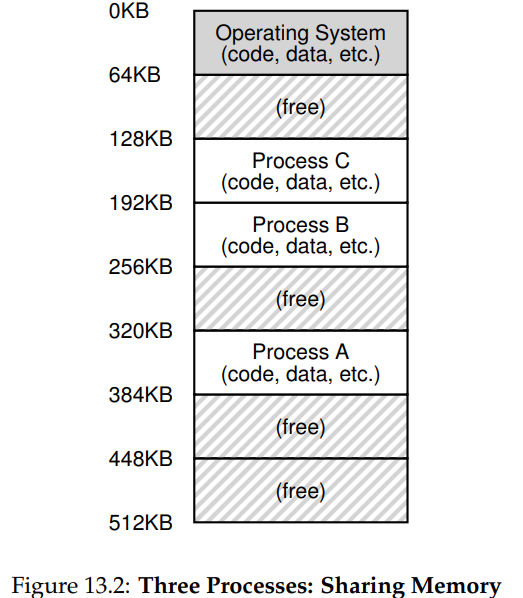
여러개의 프로세스가 존재하는 환경에서 각 프로세스는 자기가 할당받은 메모리에만 접근해야 한다. 그 외의 프로세스가 가진 메모리를 읽거나 변경하는 경우는 존재해서는 안된다.
메모리 가상화 : 하나의 물리 메모리를 공유하는 다수의 프로세스에게 각 프로세스는 마치 자신이 물리메모리 주소 0부터 시작하는 하나의 전체 물리 메모리를 사용하고 있는것처럼 해주는 운영체제의 기능
주소 변환
하드웨어 기반 주소 변환이라고도 부른다.
프로그램의 모든 메모리 참조값을 실제 물리적인 메모리 위치로 변환해준다.
이를 위해서는 CPU 당 1쌍씩 존재하는 2개의 하드웨어 레지스터가 필요하고, 이와 같이 CPU에서 주소변환의 역할을 하는 장치를 MMU (Memory Management Unit)이라고 부른다.
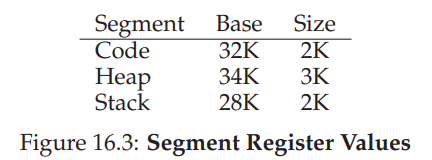
Base Register
Limit (Bound) Register
1
물리메모리 주소값 = 논리 메모리주소값 + Base Register 값
Limit Register는 프로세스가 자신의 메모리 주소값만을 접근함을 보장시켜준다. 예를 들어서 Limit Register가 16KB 면 , Base + 논리 메모리주소값이 16KB가 넘게되면 예외가 떨어진다.
동적 재배치
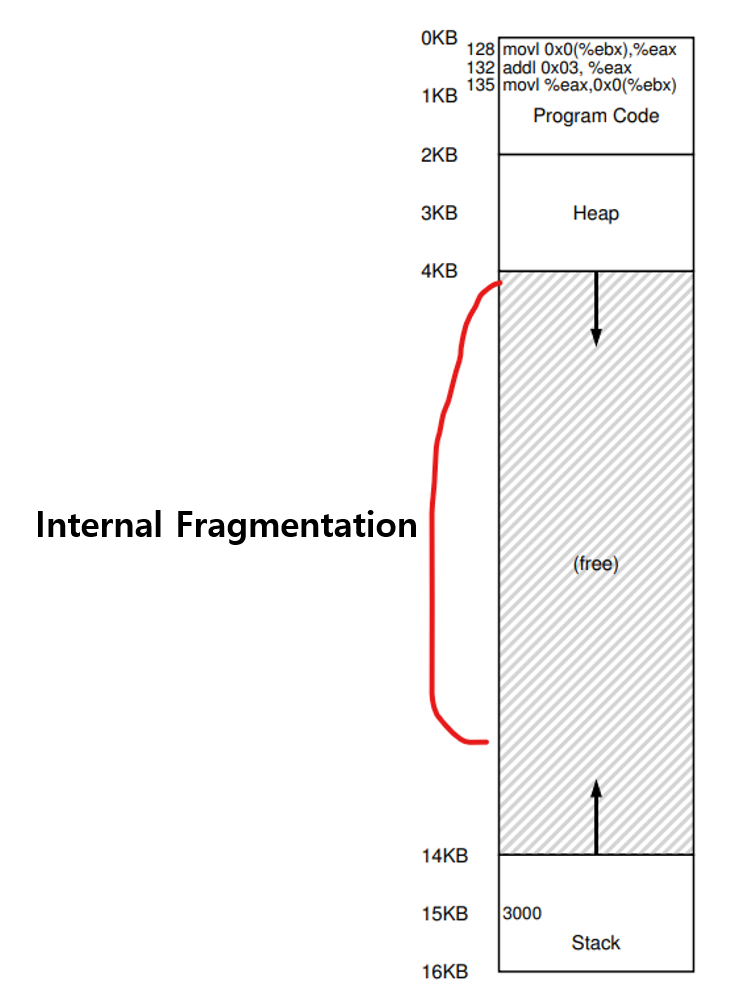
동적 재배치 (dynamic reloadling) : Base , Limit Register를 이용하여 프로세스의 메모리 주소를 변환하는데, 프로세스 메모리 주소를 쪼개지 않고 통째로 배치한다. 즉 프로그램 전체 메모리 주소가 4GB라면 실제로 사용되는 공간이 100MB 이하여도 4GB가 로딩되야하는 방식으로 메모리 낭비가 매우 심하다. 이처럼 할당된 영역에서 사용되지 않아서 낭비되는 메모리를 Internal Fragmentation (내부 단편화)라고 부른다.
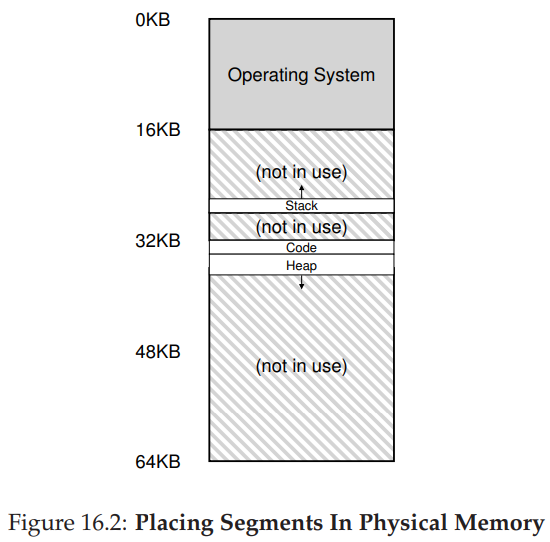
Segmentation
MMU마다 하나의 Base, Limit Register값이 아닌 세그먼트라는 단위별로 Base,Limit Register 값이 존재한다. 즉 전체 프로세스를 메모리에 올리는게 아니라, 프로세스를 세그먼트라는 단위로 쪼개서 올렸다 내렸다를 반복한다.
( * 세그먼트 : 특정 길이를 가지는 연속적인 메모리 주소 공간 )
Segment 별로 메모리 크기가 동일하게 할당되지 않아도 된다. 즉 아래와 같이 코드 세그먼트 ,힙 세그먼트 , 스택 세그먼트로 나누어 할당될 수도 있다.
동적 재배치 방식에 비해 얻는 장점 : 운영체제가 각 주소 공간을 세그먼트 단위로 가상 주소 공간을 물리 메모리에 재배치하기 때문에 전체 주소 공간이 하나의 Base ,Limit Register 값을 갖는 형태보다 메모리를 절약할 수 있다.
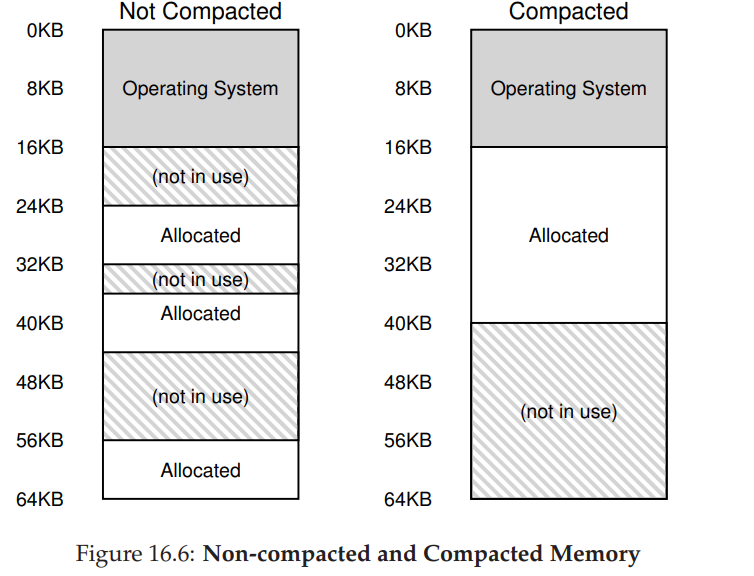
단점 : 세그먼트의 크기가 제각각이기 떄문에, Segment가 메모리에서 빠지면 크기가 다른 잔여메모리 공간이 생긴다. (External Fragmentation , 외부단편화)
위 단점의 해결방법으로 기존의 세그먼트를 정리하여 , 물리 메모리를 압축하는 방법이 있다.
Direct Path I/O을 제외한 모든 블록 I/O는 메모리 버퍼캐시에 해당 블록이 있는지 확인하고 없으면 물리 I/O가 발생한다.
인덱스 루트 블록을 읽을떄 , 인덱스 루트 블록을 통해 얻은 ROWID값으로 브랜치 블록을 읽을때 , 브랜치 블록에서 얻은 ROWID값으로 리프 블록을 읽을때 , 리프 블록에서 읽은 ROWID값으로 테이블 블록 읽을 때 , Full Scan시 모두 메모리 버퍼 캐시를 먼저 확인한다.
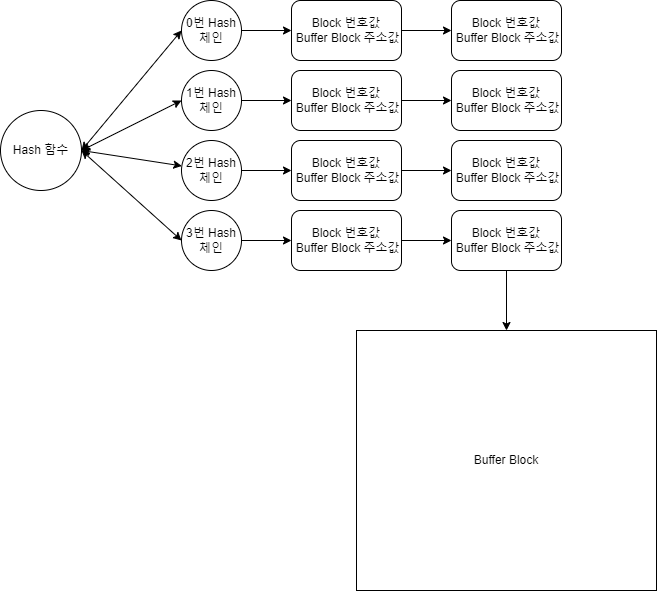
메모리 버퍼 캐시의 구조
해시구조로 관리 , 해시 함수에 입력값을 넣어 나온 해시값으로 몇번 해시 Chain에 속해있는지 확인하고 , 해당 Chain에 연결되어 있는 버퍼 헤더를 순차 탐색한다. 결과값이 있다면 캐시된 버퍼 블록으로부터 데이터을 읽어오고 , 결과값이 없다면 물리 I/O가 발생하고 , 읽기 전에 버퍼 블록에 캐싱한다.
메모리 공유 자원에 대한 직렬화
버퍼캐시는 SGA 구성요소로 프로세스간 공유 자원임. 즉 동시성이슈가 발생할 수 있어 동기화 작업이 필요함
Cache Buffer Chain Latch : 해시 체인에 접근하기전 프로세스는 Latch 를 획득해야만 접근이 가능하다. 만약 한 process가 Latch를 획득했다면 다른 process는 대기한다.
코틀린의 Null 타입 안정성은 자바에서 빈번하게 볼수 있었던 NPE (Null-Pointer Exception)이 발생할 포인트를 줄여준다.
문제는 코틀린과 다른 프로그래밍 언어를 연결해서 사용할때이다. 아래와 같이 annotation 으로 nullable 여부를 판단할 수 있다면 정확한 타입을 추정할 수 있다.
1 2 3 4 5
publicclassSample{
@NotNull private String test; }
만약 annotation이 붙어있지 않다면 , Kotlin은 해당 타입을 nullable인지 아닌지 판단할 방법이 없다. 따라서 Kotlin은 해당 타입을 Platform Type으로 간주한다. Platform Type은 타입 이름뒤에 ! 기호를 붙여서 표기한다 (String!)
Platform Type은 코틀린이 Null 관련 정보를 알 수 없기 떄문에, 컴파일러는 Nullable 타입으로 처리하든, 아니든 모든 연산을 허용한다 하지만 개발자에게 전적으로 NPE을 처리할 책임이 넘어간다.
JSR-Annotation
java와 코틀린을 같이 사용할때에는 Java 코드를 만약 직접 변경할 수 있다면, 가능한 @Nullable , @NotNull annotation을 붙이는 게 안전하다.
대표적인 annotation 예시는 다음과 같다.
org.jetbrains.annotation : @Nullable , @NotNull
javax.annotation JSR-305 : @Nullable , @NonNull
Lombok :@NonNull
정리
다른 프로그래밍 언어에서 Nullable 여부를 알 수 없는 타입을 Platform type이라고 하며 , 코틀린 컴파일러는 이에 대한 연산을 제약하진 않는다. 다만, 개발자가 전적으로 NPE을 핸들링 해야 한다, 따라서 Platform Type을 지양하고, 자바 쪽에서 수정이 가능하다면 Annotation 을 붙이자.
최대한 변수의 사용 스코프를 줄이는게 좋다. 예를 들어 변수가 반복문안에서만 사용된다면, 변수를 반복문 블록 내부에 작성하는 게 좋다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// 1 var user : User for( i in users.indices){ user = users[i] println("user at $i is $user") } // 2 for(i in users.indices){ val user = users[i] println("user at $i is $user") } // 3 for((i,user) in users.withIndex()){ println("user at $i is $user") }
1번예는 user를 반복문 블록 외부에서도 사용 가능하다. 반면 2,3번 예에서는 user의 스코프 블록을 for 반복문 내부로 제한한다.
2번,3번예는 변수를 반복문 내부로 감추고, 3번예의 경우에는 구조 분해 선언을 통해 변수를 초기화하고 있다. 이렇게 변수의 스코프를 좁게 만듦으로서 갖는 장점은 프로그램 변경 요소를 줄여, 이해하기 쉽고 디버깅이 쉽게 만든다.
반대로 변수의 스코프 범위가 너무 넓으면 다른 개발자에 의해 변수가 잘못 사용될 가능성이 있다. 따라서 변수는 정의할때 초기화되는게 가장 좋다.
1 2 3 4 5 6 7 8 9 10 11 12 13
//1 val user:User if(hasValue){ user = getValue() } else{ user = User(); } //2 val user:User = if(hasValue){ getValue() }else { User() }
위 코드에서처럼 2번과 같이 선언과 동시에 초기화하는것이 좋다. 만약 여러 프로펕치를 한꺼번에 설정해야 한다면 구조분해 선언을 활용하는게 좋다.
1 2 3 4 5 6 7
fun updateWeather(degrees: Int){ val(description, color) = when{ degrees <5 -> "cold" to Color.BLUE degrees >23 -> "mild" to Color.YELLOW else -> "hot" to Color.RED } }
클래스,프로퍼티와 같은 요소가 var 또는 mutable 객체를 사용하면 상태를 가질 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classBankAccount{ // 가변 상태 var balance = 0.0 private set fun deposit(depositAmount :Double){ balance += depositAmount } @Throws(InsufficientFunds::class) fun withdraw(widthdrawAmount : Double){ if (balance < widthdrawAmount){ throw InsufficientFunds() } balance -= widthdrawAmount } }
classInsufficientFunds :Exception()
위처럼 BankAccount 클래스는 잔액을 나타내는 변화할 수 있는 상태가 있다, 변화할 수 있는 상태를 가지는 요소는 다음과 같은 단점을 가진다.
프로그램을 이해하고 디버깅하기 힘들어진다. 오류시 상태 변경을 추적해야 한다.
멀티쓰레드 환경에서 동기화가 필요하다
테스트가 어렵다. 모든 상태에 대해서 테스트를 염두해두어야 한다.
상태변경에 따른 추가적인 조치가 필요할수도 있다. 예를 들면 항상 정렬된 경우로 유지되야할경우 값이 추가되었을떄 정렬작업이 필요하다.
반면 불변성을 유지하였을때 갖는 장점은 다음과 같다.
한번 객체의 상태가 정의되고 나서 변경되지 않으므로, 코드 이해가 쉽다.
병렬 처리에 안전
방어적 복사본을 만들지 않아도 된다.
Set,Map의 Key로 사용이 가능하다. 요소의 값이 변경되지 않기 때문이다.
멀티쓰레드환경에서 쓰레드간 공유되는 변수의 값을 변경할때 가변상태를 가지는 경우 값이 부정확하게 나올 수도 있다.
1 2 3 4 5 6 7 8 9 10 11
fun main(){ var num = 0 for (i in 1..1000){ thread { Thread.sleep(10) num+=1 } } Thread.sleep(5000) println(num) }
위 연산은 매번 실행할떄마다 공유변수에 값을 여러 쓰레드에서 변경함으로 , 연산이 덮어씌워지는 경우가 생겨 다른 값이 나온다. 이를 동기화하려면 아래와 같이 공유변수에 Lock을 걸어서, 접근을 제한하고 순차적으로 값을 증가시켜야 한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
fun main(){ var lock = Any() var num = 0 for (i in 1..1000){ thread { Thread.sleep(10) synchronized(lock){ /*Lock을 획득하고 공유변수에 접근가능하도록 동기화*/ num+=1 } } } Thread.sleep(5000) println(num) }
Kotlin에서 가변성을 제한하는 방법
Kotlin은 언어차원에서 가변성을 제한할수 있는 방법을 설계하였다.
val
Kotlin은 읽기 전용 프로퍼티 (val)을 사용하여, 변수에 재할당이 불가능하도록 만들 수 있다 (java의 final과 유사) 사실 val을 사용한다고 해서 불변성이 보장되는 것은 절대 아니고, 단지 재할당이 불가능하게 setter를 금지한다.
1 2
val x = mutableListOf(1,2,3)\ x.add(4) // 가변
부가적인 내용인데, val는 var로 overriding 이 가능하다.
1 2 3 4 5 6 7
interfaceElement{ val active : Boolean }
classActualElement : Element{ override var active: Boolean = false }
가변 Collection과 읽기 전용 Collection (read-only)
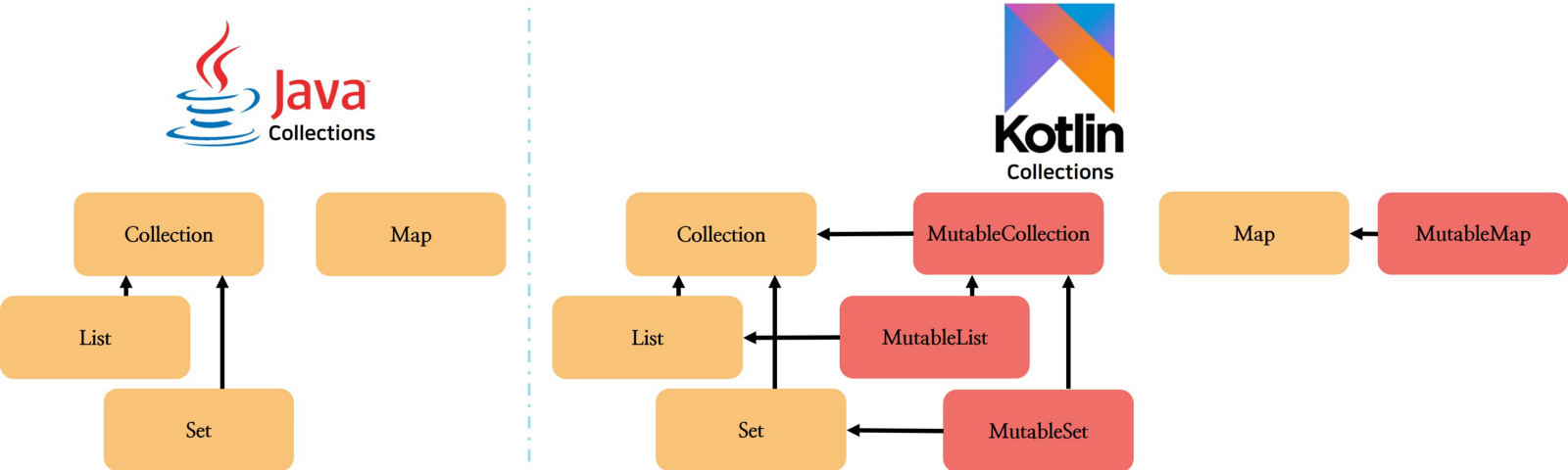
Kotlin은 Collection을 MutableCollection과 읽기 전용인 Collection으로 구분한다.
Kotlin은 Collection , Set ,List를 기본적으로는 읽기 전용으로 내부의 상태를 변경하기 위한 method를 제공하지 않는다. MutableCollection , MutableSet , MutableList 인터페이스는 읽기 전용 인터페이스를 상속받아서, 추가적으로 변경을 위한 method를 붙였다.
주의해야할점은 읽기 전용 Collection 을 가변 Collection으로 downcasting하면 안된다는 점이다.
1 2 3 4
val list = listOf(1,2,3) if (list is MutableList){ list.add(4) // java.lang.UnsupportedOperationException 예외 발생 }
Jvm에서 listOf는 Java의 List 인터페이스를 구현한 Array.ArrayList 객체를 반환하는데 이는 add,set 을 모두 가지고 있기에 MutableList로 다운캐스팅이 된다. 하지만 Arrays.ArrayList 객체는 이러한 연산을 구현하고 있지 않기 떄문에 위와 같이 UnsupportedOperationException이 터진다.
읽기 전용 Collection에서 MutableCollection으로 꼭 변경해야 한다면 , copy를 사용해서 변경해야 한다.
1 2 3 4
fun main(){ val list = listOf(1,2,3) list.toMutableList(); // 새로운 객체 반환 }
이렇게 구현하면 기존 객체는 새로 반환된 객체에 영향받지 않고 수정이 가능하다.
Data Class의 Copy
immutable 객체는 자기 자신의 상태가 일부 다른 경우에도 새로운 객체를 만들어야 되기 때문에, 자신의 일부를 수정해서 새로운 객체를 만들어 줄 수 있는 method를 가져야 한다.
이떄 data 한정자를 붙이면 자동으로 copy method를 만들어주는데, copy method는 모든 기본생성자 프로퍼티가 동일한 새로운 객체를 만들어 낼 수 있다. 따라서 원래의 불변객체가 존재하는데, 특정 상태만 바꾼 새로운 객체를 만들어내고 싶다면 copy method를 활용하면 된다.
1 2 3 4 5 6 7
data class Account(val money:Int,val owner:String) fun main(){ val myPoorAccount = Account(10000,"김찬수") val myHappyAccount = myPoorAccount.copy(money = 1000_000_000); println(myHappyAccount) }