비선점형 (협력형) 멀티 태스킹 (non-preemptive multitasking)으로 실행을 일시 중단(suspend) 하고 재개(resume) 할 수 있는 여러 진입 지점을 허용한다.
서로 협력해서 실행을 주고받으면서 작동하는 여러 서브루틴을 말한다.
일반적인 서브루틴은 오직 한 가지 진입 지점만을 가진다. 함수를 호출하는 부분이며, 그때마다 활성 레코드 (activation record)가 스택에 할당되면서 서브루틴 내부의 로컬 변수등이 초기화 된다. 또한 서브루틴에서 반환되고 나면 활성 레코드가 스택에서 사라지기 떄문에 모든 상태를 잃어버린다.
1 2 3 4 5 6 7 8 9
fun main(){ //main routine val extension = getFileExtension("cs.txt") }
fun getFileExtension(fileName:String) :String{ // subroutine return fileName.substringAfter(".") }
fun log(msg:String , self : Any?)= println("Current Thread : ${Thread.currentThread().name} / this : $self :$msg")
fun main(){ log("main routine started",null) yieldExample() log("main routine ended",null) }
fun yieldExample(){ runBlocking{ //내부 코루틴이 모두 끝난뒤 반환 launch { log("1",this) yield() // log("3",this) yield() log("5",this) } log("after first launch",this) launch { log("2",this) yield() log("4",this) yield() log("6",this) } log("after second launch",this) }
}
실행로그
1 2 3 4 5 6 7 8 9 10
Current Thread : main / this : null :main routine started Current Thread : main / this : BlockingCoroutine{Active}@33e5ccce :after first launch Current Thread : main / this : BlockingCoroutine{Active}@33e5ccce :after second launch Current Thread : main / this : StandaloneCoroutine{Active}@2ac1fdc4 :1 Current Thread : main / this : StandaloneCoroutine{Active}@3ecf72fd :2 Current Thread : main / this : StandaloneCoroutine{Active}@2ac1fdc4 :3 Current Thread : main / this : StandaloneCoroutine{Active}@3ecf72fd :4 Current Thread : main / this : StandaloneCoroutine{Active}@2ac1fdc4 :5 Current Thread : main / this : StandaloneCoroutine{Active}@3ecf72fd :6 Current Thread : main / this : null :main routine ended
위 코드를 분석하기 전에 각각 함수가 하는 역할을 정리하면 다음과 같다.
runBlocking : coroutine builder 로서 내부 코르틴이 모두 끝난 다음에 반환된다.
launch : coroutine builder로서 , 넘겨받은 코드 블록으로 새로운 코르틴을 생성하고 실행시켜준다.
yield : 해당 코르틴이 실행권을 양보하고, 실행 위치를 기억하고, 다음 호출때는 해당 위치부터 다시 실행한다.
위 코르틴에서 1,3,5를 출력하는 코르틴과 2,4,6를 출력하는 코르틴이 서로 실행권을 양보해가면서 실행된다. 한가지 유의할점은 마치 병렬적으로 실행되는 것처럼 보이지만 다른 쓰레드가 아니라 하나의 쓰레드에서 수행된다는 점이다. 따라서 Context Switching 도 발생하지 않는다.
Launch coroutine Builder는 Job 객체를 반환한다. Job은 N개 이상의 coroutines의 동작을 제어할 수도 있으며, 하나의 coroutines 동작을 제어할수도 있다.
1 2 3 4 5 6 7 8 9 10
suspend fun main()= coroutineScope { // Job 객체는 하나이상의 Coroutine 의 동작을 제어할 수 있다. val job : Job = launch { delay(1000L) println("World!") } println("Hello,") job.join() println("Done.") }
Async는 사실상 Launch와 같은일을 수행하는데, 차이점은 Launch는 Job객체를 반환하는 반면 , Async는 Deffered를 반환한다.
1 2 3 4 5 6 7 8 9 10 11 12 13
publicinterfaceDeferred<outT> : Job{
public suspend fun await(): T public val onAwait: SelectClause1<T> @ExperimentalCoroutinesApi public fun getCompleted(): T @ExperimentalCoroutinesApi public fun getCompletionExceptionOrNull(): Throwable? }
Deffered는 Job을 상속한 클래스로서, 타입 파라미터가 있는 제너릭 타입이며, Job과 다르게 await 함수가 정의되어 있다.
Deffered의 타입 파라미터는 Deffered 코루틴이 계산 후 돌려주는 값의 타입이다. 즉 Job은 Deffered<Unit>라고 생각할수도 있다.
정리하면 async는 코드 블록을 비동기로 실행 할 수 있고, async가 반환하는 Deffered의 await를 사용해서 코루틴이 결과 값을 내놓을떄까지 기다렸다가 결과값을 받아올 수 있다.
이떄 비동기로 실행할떄 제공되는 코루틴 컨텍스트에 따라 하나의 Thread안에서 제어만 왔다 갔다 할수도 있고, 여러 Thread를 사용할 수도 있다.
1 2 3 4 5 6 7 8 9 10 11
fun sumAll(){ runBlocking { val d1 = async { delay(1000L); 1 } println("after d1") val d2 = async { delay(2000L); 2 } println("after d2") val d3 = async { delay(3000L); 3 } println("after d3") println("1+2+3 = ${d1.await()+d2.await()+d3.await()}") } }
실행로그를 보면 다음과 같다.
1 2 3 4
after d1 after d2 after d3 1+2+3 = 6 // 코루틴이 결과값을 내놓을떄까지 기다렸다가 결과값을 받아온다.
만약 위 코드를 직렬화해서 실행하면 최소 6초의 시간이 걸리겠지만, async로 비동기적으로 실행하면 3초가량이 걸리며 더군다나 위 코드는 별개의 thread가 아니라 main thread 단일 thread로 실행되어 이와 같은 성능상 이점을 얻을수 있다.
특히 이와 같은 상황에서 코루틴이 장점을 가지는 부분은 I/O로 인한 장시간 대기 , CPU 코어수가 작아 동시에 병렬적으로 실행 가능한 쓰레드 개수 한정된 상황 이다.
코루틴 컨텍스트
Launch , Async 등은 모두 CoroutineScope의 확장함수로 실제로 CoroutineScope는 CoroutineContext 필드를 이런 확장함수 내부에서 사용하기 위한 매개체 역할을 수행한다. 원한다면 launch,aync 확장함수에 CoroutineContext를 넘길수도 있다.
/** * Launches a new coroutine without blocking the current thread and returns a reference to the coroutine as a [Job]. * The coroutine is cancelled when the resulting job is [cancelled][Job.cancel]. * * The coroutine context is inherited from a [CoroutineScope]. Additional context elements can be specified with [context] argument. * If the context does not have any dispatcher nor any other [ContinuationInterceptor], then [Dispatchers.Default] is used. * The parent job is inherited from a [CoroutineScope] as well, but it can also be overridden * with a corresponding [context] element. * * By default, the coroutine is immediately scheduled for execution. * Other start options can be specified via `start` parameter. See [CoroutineStart] for details. **/ public fun CoroutineScope.launch( context: CoroutineContext = EmptyCoroutineContext, start: CoroutineStart = CoroutineStart.DEFAULT, block: suspend CoroutineScope.() -> Unit ): Job { //... }
// --------------- async ---------------
/** * Creates a coroutine and returns its future result as an implementation of [Deferred]. * The running coroutine is cancelled when the resulting deferred is [cancelled][Job.cancel]. * The resulting coroutine has a key difference compared with similar primitives in other languages * and frameworks: it cancels the parent job (or outer scope) on failure to enforce *structured concurrency* paradigm. * To change that behaviour, supervising parent ([SupervisorJob] or [supervisorScope]) can be used. * * Coroutine context is inherited from a [CoroutineScope], additional context elements can be specified with [context] argument. * If the context does not have any dispatcher nor any other [ContinuationInterceptor], then [Dispatchers.Default] is used. * The parent job is inherited from a [CoroutineScope] as well, but it can also be overridden * with corresponding [context] element. * * By default, the coroutine is immediately scheduled for execution. * Other options can be specified via `start` parameter. See [CoroutineStart] for details. * */ public fun <T> CoroutineScope.async( context: CoroutineContext = EmptyCoroutineContext, start: CoroutineStart = CoroutineStart.DEFAULT, block: suspend CoroutineScope.() -> T ): Deferred<T> { //... }
그렇다면 CoroutineContext가 하는 역할은 무엇일까?
코루틴이 실행중인 여러 작업과 디스패처를 저장하는 일종의 맵으로 이 CoroutineContext를 사용해 다음에 실행할 작업을 선정하고, 어떻게 Thread에 배정할지에 대한 방법을 결정한다.
fun context(){ runBlocking { launch { // 부모 컨텍스트를 사용 println("use parent context :${getThreadName()}") } launch(Dispatchers.Unconfined) { // 특정 Thread에 종속되지 않고, Main Thread 를 사용 println("use main thread :${getThreadName()}") } launch(Dispatchers.Default){ println("use default dispatcher :${getThreadName()}") } launch(newSingleThreadContext("MyOwnThread")){ // 직접 만든 새로운 Thread 사용 println("use thread that i created : ${getThreadName()}") } } }
실행로그를 보면 같은 launch 확장함수를 사용한다고 하더라도 실행되는 CoroutineContext에 따라 다른 Thread상에서 코루틴이 실행됨을 확인할 수 있다.
1 2 3 4
use main thread :main use default dispatcher :DefaultDispatcher-worker-1 use parent context :main use thread that i created : MyOwnThread
Coroutine Builder 와 Suspending Function
앞선 Launch , Async , runBlocking , CoroutineScope모두 코루틴 빌더라고 , 새로운 코루틴을 만들어주는 함수이다.
delay , yield 함수는 일시중단 함수로 이외에도 다른 일시중단 함수들이 존재한다.
Java와 다르게 Kotlin에서는 람다안에서 return 을 사용하면 람다로부터만 반환되는게 아니라, 그 람다를 호출하는 함수가 실행을 끝내고 반환된다.
이를 Non-Local Return 이라고 부른다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// java List.of("a","b","c").forEach((item)-> { if (item.equals("a")){ return; } // b,c에 대해서도 실행됨. }); // kotlin listOf("a","b","c").forEach { if (it.equals("a")){ return; } println(it) // a에서 종료됨 }
Non-Local Return 이 적용되는 상황
람다 안의 return 문이 바깥쪽 블록의 함수를 반환시킬 수 있는 상황은 람다를 인자로 받는 함수가 인라인 함수인 경우에만 가능하다. 즉 위의 forEach 함수는 인라인이기에 Non-local return 이 가능한 것이다.
Label을 사용한 Local return
람다식안에서 람다의 실행을 끝내고 람다를 호출했던 코드의 실행을 이어서 실행하기 위해서는 Local Return을 사용하면 된다.
Non-Local Return 과 구분하기 위해서 Local Return에는 레이블을 추가해야 한다.
1 2 3 4 5 6 7 8 9 10
fun lookForBob(people : List<Person>){ people.forEach label@{ if (it.name == "Bob"){ println("found Bob!") return@label } } // Local Return을 사용하면 람다가 종료되고 람다 아래의 코드가 실행된다. println("end of function") }
또는 인라인 함수의 이름을 label로 사용하여도 위의 코드와 동일하다.
1 2 3 4 5 6 7 8 9 10
fun lookForBob(people : List<Person>){ people.forEach { if (it.name == "Bob"){ println("found Bob!") return@forEach } } println("end of function") }
Anonymous Function 을 사용한 깔끔한 Local Return
앞선 Local Return 방식은 레이블을 통해 구현하여, 조건 분기에 따라 여러번 Return 문을 기입해야 할떄는 반환문이 장황해 질 수 있다.
Anonymous Function은 (익명,무명함수) 코드 블록을 함수에 넘길때 사용할 수 있는 방법 중에 하나로 일반 함수와 차이점은 함수 이름과 파라미터 타입을 생략 가능하다는 점이다.
1 2 3 4 5 6 7 8 9
fun lookForBob(people : List<Person>){ people.forEach (fun(person){ if (person.name == "Bob"){ println("found Bob!") return } println("end of anonymous function") })
기본적으로 익명함수도 반환타입을 기입해줘야 하지만, 함수 표현식 (expression body)를 바로 쓰는 경우에는 반환타입 생략이 가능하다.
정리
Inline 함수의 경우 람다안의 return문이 바깥쪽 block의 함수를 반환시키는 Non-Local Return을 사용할 수 있다.
Anonymous Function을 활용하면 람다를 대체해서 Local Return을 깔끔하게 Label 사용없이 작성 가능하다.
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs); consumer.subscribe(Arrays.asList(TOPIC_NAME));
while (true){ ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1)); logger.info("record :{}" , records); for (ConsumerRecord<String, String> record : records) { logger.info("{}",record); } } } }
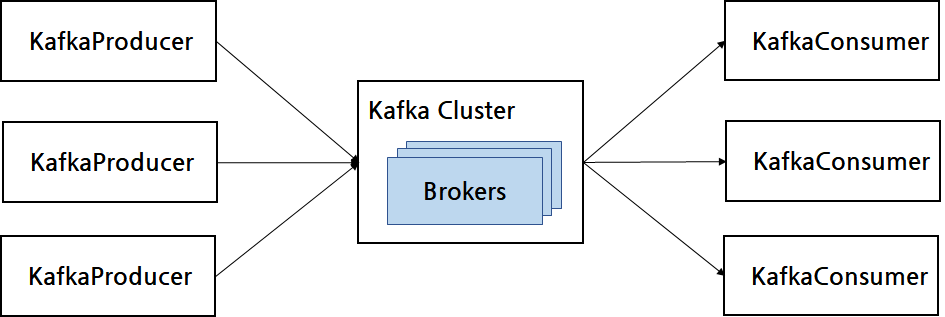
Consumer Group 을 통해 Consumer의 목적을 구분한다. 동일 기능을 수행하는 app인 경우 하나의 Group으로 묶어서 관리하며, Consumer Group을 기준으로 Consumer Offset을 관리한다. 따라서 subscribe method를 사용해 특정 토픽을 구독하는 경우에 Consumer Group을 선언해야 한다.
Consumer Group을 선언하지 않으면 어떤 그룹에도 속하지 않는 Consumer로 동작하게 된다.
Consumer는 poll method를 호출하여 데이터를 가져와 처리한다. 이떄 Duration 타입의 인자값을 받는데, 이 값은 Consumer 버퍼에 데이터를 가져오는 타임아웃 간격을 뜻한다.
파티션 할당 Consumer
Consumer 운영시 위와 같이 subscribe 형태로 특정 토픽을 구독하는 형태로 사용하는것 외에도 파티션까지 명시적으로 선언할 수 있다.
1
consumer.assign(TOPIC_NAME,PARITITON_NUM);
이때는 Consumer가 특정 Topic의 특정 파티션에 직접적으로 할당됨으로 rebalancing 과정이 안일어나는데 rebalancing에 대한 설명은 아래에 정리하였다.
Consumer 운영 방식
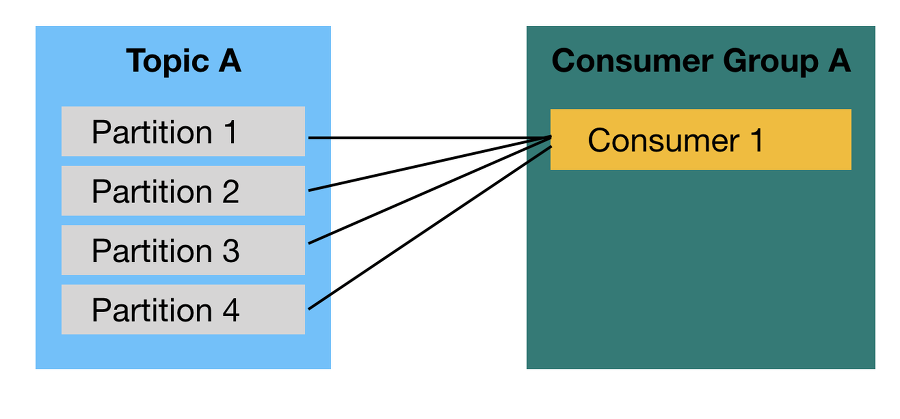
1개 이상의 Consumer로 이루어진 Consumer Group을 운영한다. 이떄 Consumer들은 Topic의 1개 이상의 파티션들에 할당되어 데이터를 가져갈 수 있다.
이떄 1개의 파티션은 최대 1개의 Consumer에 할당가능한 반면 1개의 Consumer는 여러 개의 Partition에 할당될 수 있다. 따라서 Consumer Group의 Consumer개수는 가져가고자 하는 Topic의 파티션 개수보다 같거나 작아야 한다.
물론 Consumer개수가 파티션의 개수보다 많게 설정할 수는 있겠지만, 파티션은 1개의 Consumer까지만 가질 수 있기 때문에 놀고 있는 Consumer는 Thread만 차지하고 아무 데이터도 처리하지 않음으로 불필요하다.
Consumer Group은 다른 Consumer Group과 격리되는 특징을 가지고 있다. 따라서 Kafka Producer가 보낸 데이터를 각기 다른 역할을 하는 Consumer Group끼리 영향을 받지 않게 처리할 수 있다는 장점을 가진다.
Rebalancing
Rebalancing : Consumer Group으로 이루어진 Consumer 들 중 일부 Consumer에 장애가 발생하면 , 장애가 발생한 Consumer에 할당된 partition은 장애가 발생하지 않은 Consumer에 소유권이 넘어가는 것
Consumer가 추가되거나 장애발생으로 제외되는 상황에서 발생한다.
Rebalancing 발생 시 Consumer들이 Topic의 데이터를 읽을 수 없기 떄문에 빈번히 Rebalancing이 일어나는 상황은 피해야 한다.
Broker중 한 대가 Group Coordinator(그룹 조정자)로서, Rebalancing을 발동시키는 역할을 한다.
Rebalancing 직전에 데이터를 커밋하지 않아서, consumer가 처리했던 데이터의 오프셋이 기록되지 않고, 또 다시 데이터를 중복처리하는 경우가 생길수도 있다. org.apache.kafka.clients.consumer.ConsumerRebalanceListener 는 rebalancing 직후 , 직전에 호출되는 method를 가지고 있다.
1 2 3 4 5 6 7 8 9 10
publicclassRebalanceListenerimplementsConsumerRebalanceListener{ @Override publicvoidonPartitionsRevoked(Collection<TopicPartition> partitions){ // partition 할당 완료시 호출되는 메소드 } @Override publicvoidonPartitionsAssigned(Collection<TopicPartition> partitions){ // partition 할당이전에 호출되는 메소드로 offset commit 하는 로직이 주로 들어간다. } }
Commit
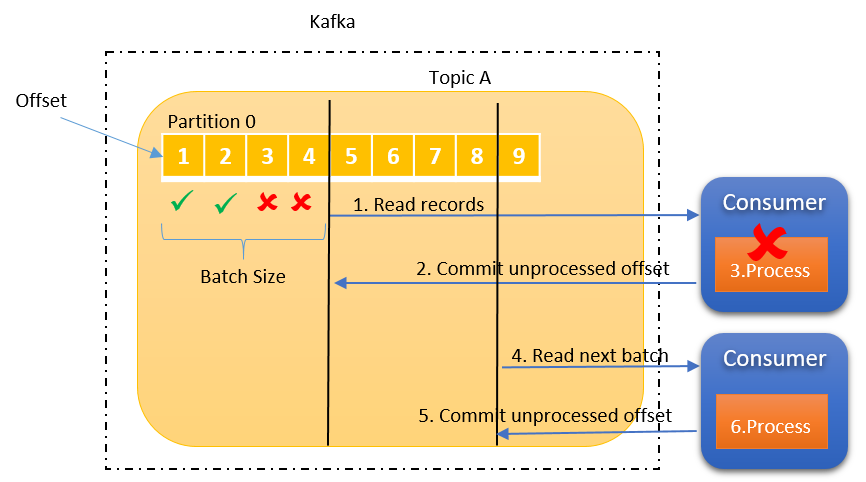
Consumer는 Broker로부터 Data를 어디까지 가져갔는지 Commit을 통해 기록한다.
특정 Topic의 Partition을 어떤 Consumer Group 이 몇 번쨰까지 가져갔는지 Broker 내부에서 사용되는 내부 토픽에 기록된다.
offset commit은 Consumer Application에서 명시적/비명시적으로 수행가능한데, default는 poll method가 수행될때 일정간격마다 offset을 commit하도록 설정되어 있다. 이를 비명시 오프셋 커밋이라고 부른다.
1 2
enable.auto.commit=true auto.commit.interval.ms=설정된시간값 // 설정시간값이후에 그 시점까지 읽은 레코드의 오프셋을 커밋한다.
비명시 오프셋 커밋의 장점은 poll method 실행시 auto.commit.interval.ms 설정값 이후면 오프셋을 자동으로 커밋해주어, 코드상 수정이 필요없지만 반대로 단점은 poll method 실행 이후에 rebalancing이나 consumer 장애발생시에 오프셋이 커밋되지 않아, 데이터 중복이나 유실이 일어날 수 있는 가능성이 있다.
명시적으로 오프셋 커밋을 수행하려면 commitSync method를 통해 poll method를 통해 반환된 record의 가장 마지막 오프셋을 기준으로 커밋을 수행하면 된다. commitSync method는 동기적으로 broker에게 응답을 기다리지만 이를 비동기적으로 수행하고 싶다면 commitAsync method를 실행하면 된다.
Broker로 Commit을 요청한 이후에 Commit이 완료될떄까지 기다린다. 따라서 비동기 오프셋 커밋보다 데이터 처리량은 떨어진다.
가장 최근에 받아온 레코드의 오프셋을 커밋하는 경우
1 2
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1)); consumer.commitSync(); // 동기 오프셋커밋 (가장 마지막 레코드의 오프셋을 커밋함)
개별 레코드 단위로 커밋하는 경우로, topic,partition,offset등의 정보를 담은 map을 파라미터로 넘겨준다. 이때 offset은 넘겨준값부터 레코드를 넘겨주기 떄문에 + 1 한 값을 넣는다.
1 2 3 4 5 6 7 8 9
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1)); Map<TopicPartition, OffsetAndMetadata> currentOffset = new HashMap<>();
for (ConsumerRecord<String, String> record : records) { currentOffset.put( new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1,null)); consumer.commitSync(currentOffset); }
비동기 오프셋 커밋
Broker로 Commit을 요청한 이후에 응답을 기다리지 않고, 데이터를 처리한다.
1
consumer.commitAsync();
consumer.commitAsync method는 콜백 인터페이스를 제공하며 , 비동기요청이 완료되었을때 수행할 행동을 지정할 수 있다.
1 2 3 4 5 6
consumer.commitAsync(new OffsetCommitCallback() { @Override publicvoidonComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception){ // commitAsync 응답을 받아서 처리하는 callback method } });
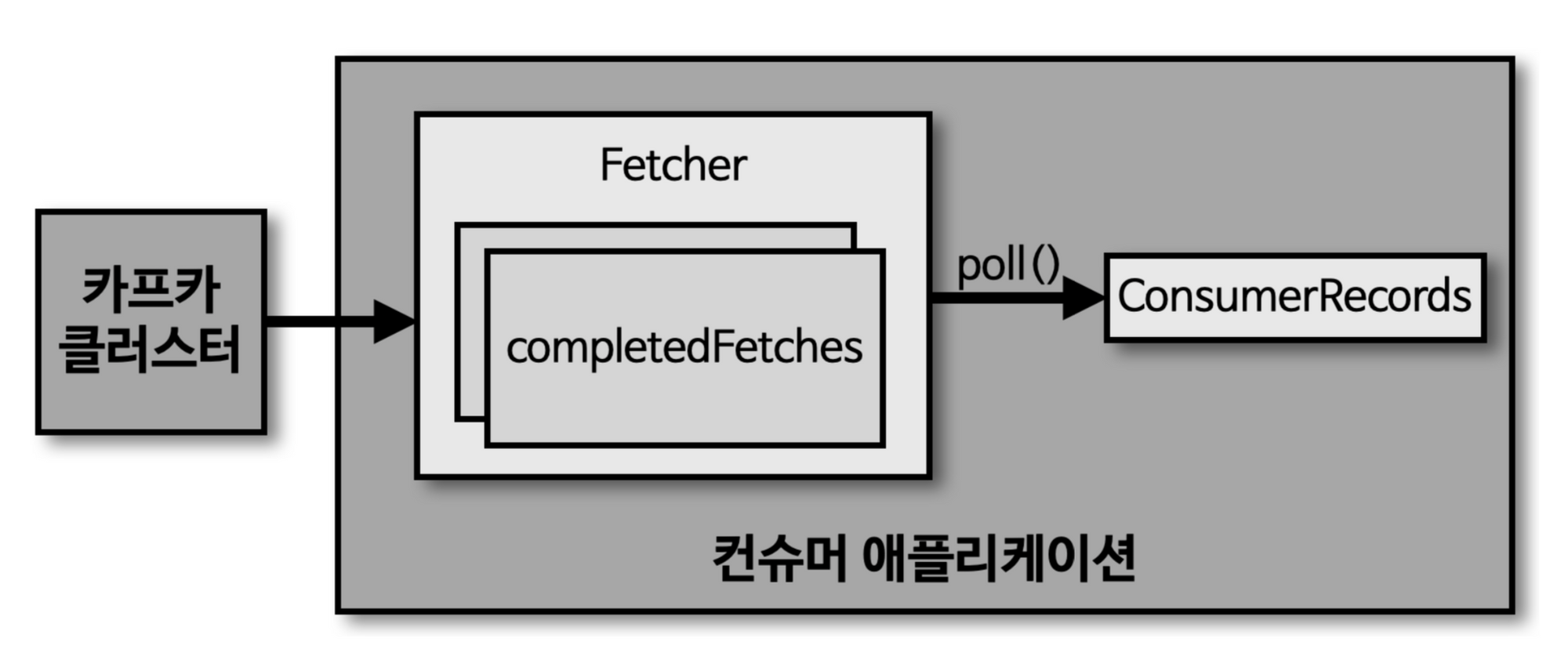
Fetcher instance
1
consumer.poll(Durtaion.ofSeconds(1));
consumer는 poll method를 통해 record를 반환받지만, 실제로 이 method가 실행될떄 Broker cluser로부터 데이터를 가져오는 것이 아니라, Consumer Application 실행시점에 내부에서 미리 Fetcher Instance가 생성되어 poll method 호출전에 record를 미리 내부 Queue로 가져온다.
따라서 poll method는 Fetcher instace의 queue에 있는 record를 반환받는 것이다.
// Broker 의 토픽이름 privatefinalstatic String TOPIC_NAME = "test";
// Broker Ip 주소와 Port 번호 privatefinalstatic String SERVER = "BROKER_PUBLIC_IP_ADDR:9092";
publicstaticvoidmain(String[] args){
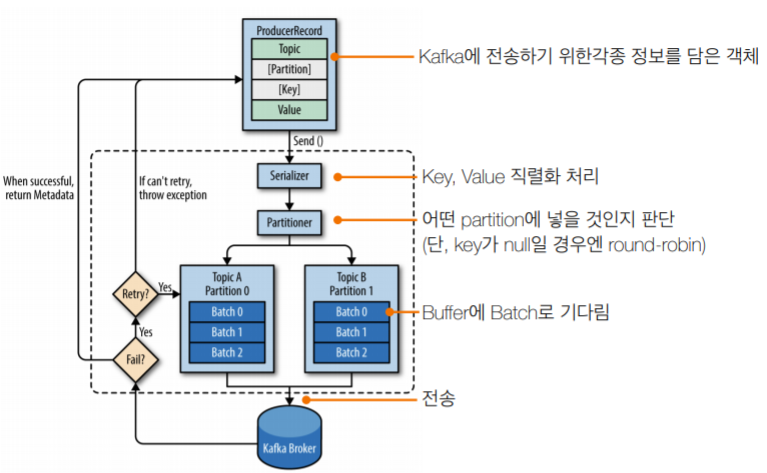
// Kafka Producer 객체를 생성하기 위한 필수 옵션 Properties config = new Properties(); config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,SERVER); // Message 키와 값을 직렬화하기 위한 직렬화 클래스 config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG , StringSerializer.class.getName()); config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // Producer 객체 생성 KafkaProducer<String,String> producer = new KafkaProducer<String, String>(config);
String testMessage = "testMessage"; // Broker로 보낼 데이터 생성 . 키를 별도로 지정하지 않으면 null이 들어가며, Key와 Value는 당연히 직렬화 클래스와 타입이 동일해야 한다. ProducerRecord<String,String> record = new ProducerRecord<>(TOPIC_NAME,testMessage); // 배치 전송 (즉각적인 전송이 아니라, 배치단위로 묶어서 전송한다. ) producer.send(record); logger.info("record : {}",record); // producer 내부 버퍼의 레코드 배치를 Broker로 전송한다. producer.flush(); producer.close(); } }
실제로 로그에 찍힌 내용을 보면 정상적으로 Broker에 Record가 송신된것을 확인할 수 있다.
추가로 send method의 return 값은 Future 객체로 원한다면 동기적으로 record를 보낸 데이터를 가져올 수 있다.
1 2 3 4
ProducerRecord<String,String> record = new ProducerRecord<>(TOPIC_NAME,testKey,testMessage); Future<RecordMetadata> result = producer.send(record); RecordMetadata recordMetadata = result.get(); logger.info("recordMetadata : {}",recordMetadata); // recordMetadata : test-0@4 0번 파티션의 4번 오프셋에 저장됨
동기로 데이터를 확인할 경우, Producer 서버는 데이터 응답 전까지 대기하는 단점이 있다. 이를 커버하기 위해서 CallBack 인터페이스도 제공된다.
Transaction은 ACID 라 하는 원자성 (Atomicity) , 일관성 (Consistency) , 격리성 (Isolation) , 지속성 (Durability) 을 보장해야 한다.
이중에 Transaction 격리 수준에 관련된 ACID 특성인 격리성만 간략하게 정리하면 , 동시에 실행되는 트랜잭션이 서로에게 영향을 미치도록 격리한다는 뜻이다.
왜 격리 수준을 나누어서 관리하는가?
격리성이란 트랜잭션이 서로에게 영향을 미치지 않도록 해야 한다는 성질인데, 이를 완벽하게 100% 보장하려면 동시성과 관련된 성능 저하가 야기된다. 예를 들면 모든 트랜잭션이 순차적으로 실행되고 끝나야만 이를 보장할 수 있다.
ANSI 표준 Transaction 격리 수준
ANSI 표준에서는 트랜잭션 격리 수준을 4단계로 나누어서 정의하고 있다.
READ UNCOMMITED (커밋되지 않은 읽기)
READ COMMITTED (커밋된 읽기)
REPEATABLE READ (반복 가능한 읽기)
SERIALIZABLE (직렬화 가능)
(1->4으로 갈수록 격리 수준이 높아지고, 동시성은 떨어진다. )
READ UNCOMMITED
커밋하지 않은 데이터를 읽을 수 있다.
Transaction A가 Transaction B 가 커밋하기 전에 수정한 데이터를 조회할 수 있다.
만약 Transaction B가 데이터를 수정하고 롤백을 해버렸는데, Transaction A는 이 ROLLBACK한 데이터를 참조하고 있는 경우 데이터 정합성 문제가 발생할 수 있다. (Dirty Read)
READ COMMITED
커밋한 데이터만 읽을 수 있다.
Dirty Read가 발생하지 않는다.
만약 Transaction A 가 데이터를 수정하고 Commit하면 , Transaction B가 Transaction A가 변경하기 전의 데이터를 읽고, Transaction A가 변경하고 나서 커밋한 뒤에 데이터를 다시 읽었을때, 값이 다르다. 즉 Tranascation B가 실행되는 도중에 Transaction A 가 값을 변경하고 커밋해버리면 다시 읽었을떄 값이 달라지는 문제이다. (NON-REPEATABLE READ)
보통 데이터베이스는 READ COMMITED 격리 수준을 기본으로 제공한다.
REPEATABLE READ
동일 Trnasaction 내에서 한번 조회한 데이터를 다시 조회할때도 동일한 값이 조회되는 격리 수준이다. 즉 NON-REPEATABLE READ가 발생하지 않는다.
만약 Transaction B가 특정 결과집합을 조회하고 나서, Transaction A가 데이터를 insert 하고 커밋하면 , Transaction B가 결과집합을 다시 조회하였을때, 데이터 값이 변경되진 않지만 추가된 상태를 읽는다. (PHANTOM READ)
SERIALIZABLE
가장 엄격한 Transaction 격리 수준으로 Dirty Read , NON-REPEATABLE READ , PHANTOM READ 어떠한 문제도 발생하지 않는다.
read - only mode의 경우에는 serializable isolation level과 유사하나 , SYS 유저가 아닌 경우에는 데이터 변경을 허용하지 않는다. 즉 일반 유저는 serializable isolation level 에서 데이터 변경까지 허용이 불가능한 격리 수준이 가장 높은 모드이다.