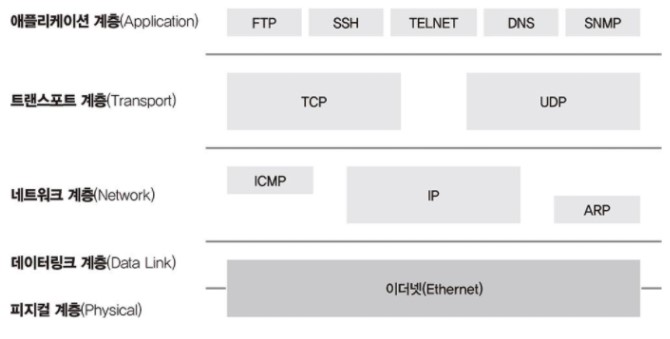
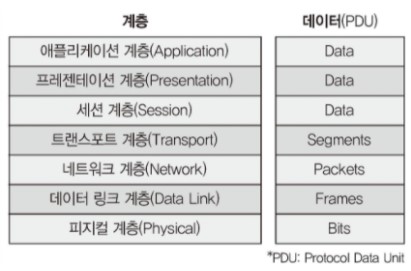
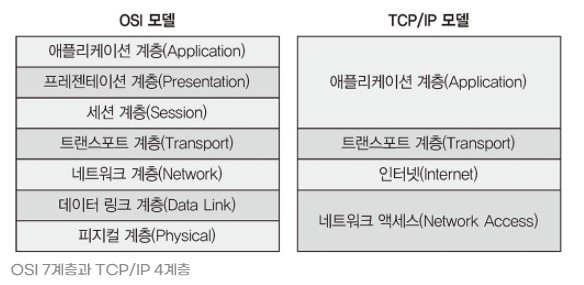
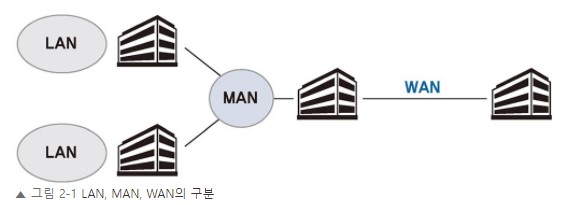
네트워크 연결 구분
네트워크는 규모에 따라 LAN,MAN,WAN 3가지로 구분된다.
1.LAN(Local Area Network) : 사용자 내부 네트워크 (근거리 통신망으로 주로 집 , 사무실 단위)
2.MAN(Metro Area Network) : 한 도시 정도를 연결하고 관리하는 네트워크
3.WAN(Wide Area Network) : 멀리 떨어진 LAN을 연결해주는 네트워크
네트워크 회선
인터넷 회선
- 인터넷 접속을 위해 통신사업자와 연결하는 회선
인터넷 가입자와 통신사업자간에는 직접 연결되는 구조가 아니라 전송 선로 공유 기술을 사용한다. 예를 들어 아파트 광랜은 아파트에서 통신사업자까지 연결한 회선을 아파트 가입자가 공유하는 구조임. 즉, 전송 선로를 공유하므로 전용 회선과 다르게 속도가 보장되지 않는다 (주변 사용량에 따라 속도가 느려질 수도 있다. )
인터넷 회선 종류는 다음과 같다.
- 광랜(이더넷) , FTFH , 동축 케이블 인터넷 , xDSL
전용 회선
- 가입자와 통신사업자 간에 대역폭(bandwith,링크 용량)을 보장해주는 서비스.
가입자와 통신사업자 간에는 전용 케이블로 연결되어 있고, 통신사업자 내부에서 TDM(Time Division Mulitiplexing) 같은 기술로 마치 직접 연결한 것처럼 통신 품질을 보장해준다.
인터넷 전용 회선
- 인터넷 회선에 대한 통신 대역폭을 보장해주는 서비스
가입자가 통신사업자와 연결되고 이 연결이 다시 인터넷과 연결되는 구조이다.
VPN (Virtual private network , 가설 사설망 )
- 물리적으로는 전용선이 아니지만, 가상으로 직접 연결한 것 같은 효과가 나도록 만들어주는 네트워크 기술
ex) 재택근무중인데 회사 사설망에 연결되어있는 것처럼 업무 가능
- 통신사업자 VPN : VPN 서비스를 ISP에서 제공하며 전용선의 거리에 비례하는 비용문제가 있다.
- 가입자 VPN : 일반 인터넷망을 이용해 가상 네트워크를 구성할 수 있다.
네트워크 구성 요소
네트워크 인터페이스 카드 (NIC)
흔히 랜카드,네트워크 카드, 네트워크 인터페이스 컨트롤러로도 불리는 네트워크 인터페이스 카드는 컴퓨터를 네트워크에 연결하기 위한 하드웨어 장치이다.
노트북과 데스크탑 PC에서는 기본적으로 온보드 형태로 장착됨으로 별도로 추가할 필요는 없으나, 서버의 경우에 여러 네트워크에 동시에 연결하거나 혹은 더 높은 대역폭이 필요한 경우, 네트워크 인터페이스 카드를 추가로 장착한다.
네트워크 인터페이스 카드의 주요 역할은 다음과 같다.
직렬화 (Serialization) : 전기적 신호를 bit열의 데이터 신호 형태로 , bit열의 데이터 신호 형태를 전기적 신호 형태로 변환시켜주는데, 이러한 상호 변환작업을 직렬화라고 한다.
MAC 주소 : 네트워크 인터페이스 카드는 고유한 MAC주소를 가지고 있어서, 받은 패킷의 도착지 MAC주소가 자신의 MAC주소가 아니면 폐기하고 맞으면 전달한다.
흐름 제어 (Flow control) : 이미 통신 중인 데이터 처리 떄문에 새로운 데이터를 받지 못하는 상황에서 데이터 유실 방지를 위해 상대방에서 통신 중지를 요청할 수 있다.